Translations
Internet Groupware for Scientific Collaboration
by Jon Udell, http://udell.roninhouse.com/ 1
The Web was invented so that scientists could use computer networks to collaborate -- that is, exchange documents, discuss them, coordinate work, create and publish collective knowledge. It was, in other words, supposed to be a groupware application. 2
Despite the popularity of the Web -- or, perhaps, because of that popularity -- it has yet to fulfill that original mission. Today's Web is more like a shotgun marriage of electronic publishing and broadcast television than it is like an engineered solution for group collaboration. True, the Internet empowers today's working scientist in ways only dreamed of even a decade ago. Yet our use of it often remains rooted in pre-Web idioms and habits -- partly because we don't fully exploit today's Internet communication tools, but mainly because we're still missing key tools and infrastructure. Consider some of the routine daily activities of a working scientist circa 2000: 3
Scheduling a meeting with a team of colleages. The meeting organizer contacts the target group by email. Negotiation of time and venue involves a tedious series of email exchanges which carry both structured data (accept/reject/postpone) and unstructured communication (agenda-setting, politicking). The Internet is utilized solely as a message transport. The messaging software has no understanding of the event-scheduling protocol, does not capture or represent the consensus of the group, and cannot shield participants from the low-level message flow in order to focus their attention on its outcome. The meeting organizer has to process and make sense of the raw message flow, unaided by any meaningful software support. 4
Of course, conventional scheduling behavior -- popping into people's offices, calling them on the phone -- never was automatable by software. But as one scientist interviewed for this report remarked wistfully, that mattered less when personal assistants were available to do these chores. Those assistants are harder to come by nowadays. So we expect the Web not just to "do things faster" but to "do more things." 5
Discussing issues with a team of colleagues. When groups can't meet face-to-face, the most well-funded may enjoy access to a videoconferencing facility. Others rely on telephone conference calls. But realtime video- and audio-conferencing modes must always be augmented by written communication. Email is the mode of choice, but for many reasons it makes a poor tool for group discussion. When messages are simply cc'd among members of the team, there's no central transcript and the conversational thread is easily lost. When messages are relayed through email aliases or listservs things are a bit better but, as we'll see, these shared spaces fail to organize group messaging in the most effective ways. 6
Monitoring the activities of colleagues in your own and related fields. In scientific collaboration, everybody has to mind everybody else's business. You pay close attention to what your immediate colleagues are doing, and try to at least keep in touch with more distant colleagues and related disciplines. Thanks to the Internet the problem here is no longer lack of information. Quite the reverse. We are flooded with more information than we can process. Much of it comes, again, in the form of a torrent of email. "I need to join some more lists," said one scientist interviewed for this report, "but I can't begin to keep up with the ones I'm already on." 7
Publishing a scientific paper. Typically the author writes the draft in Microsoft Word or, if math-intensive, FrameMaker or TeX. Often, he or she then emails the draft to reviewers. Responses come back as versions of the document with revision marking (in the case of Word), or email messages referring to parts of the document. Once submitted, the paper may be made available online -- for example, as part of the e-print archive at http://www.arxiv.org (formerly xxx.lanl.gov). Interested parties use the Internet to communicate during the preparation of the paper, and after its publication, but such collaboration is constrained by the fact that the document is never written in, and rarely read in, the Web's native HTML format. Particularly tragic, in this regard, is HTML's inability to express mathematical notation. 8
An ideal implementation of Internet groupware would enable us to work in shared electronic spaces that: 9
-
are created ad-hoc, without the help of a central authority 10
-
are accessible with free, universally-available software 11
-
are equally accessible to colleagues both inside and outside the firewall 12
-
can be strongly encrypted 13
-
are backed by a rich, transactional data store 14
These shared spaces would support applications that: 15
-
fluidly integrate rich text, equations, vector and raster images, voice, and video 16
-
are made of standard components 17
-
represent data in a standard way 18
-
encapsulate collaborative protocols (event scheduling, discussion, document review, project planning) 19
-
help people focus attention on the "important" stuff 20
Nobody would argue against these principles. But how will we get from here to there, and when? This report considers a number of products, services, technologies, and techniques that, collectively, suggest both near-term and longer-term answers to these questions. 21
The report divides into four sections: 22
-
Event Coordination. When we schedule meetings we eventually agree on a time, a place, and a group of participants. But the protocol isn't just about synchronizing calendars. It also involves discussion and negotiation. Web-based services can help us manage both the structured and semi-structured aspects of event coordination. 23
-
Group Discussion. Mailing lists, the dominant mode of group messaging, are problematic. Fortunately there are a variety of alternatives that can make shared discussion spaces easier to create, and more effective to use. 24
-
Broadcasting and Monitoring News. The physics e-print archive at www.arxiv.org has transformed the way scientists publicize their own work, and monitor the work of colleagues. A new standard for content syndication on the web can generalize and extend this process. 25
-
Scientific Publishing. TeX and LaTeX define scientific publishing for a generation of scientists. But these formats don't integrate directly into the shared spaces of the Web. The rise of XML as a universal markup language, along with vocabularies such as MathML (for mathematical notation) and SVG (for scalable vector graphics), suggests that the Web may yet reach its original collaborative goal. 26
1 Event Coordination
There are now a number of free (advertising-supported) web services that can help streamline the communication effort required to coordinate an event. They include: 27
Using any of these services you can create an "event object" in web space, and specify email addresses of people you want to invite to the event. (To simplify that chore, these services can import a variety of common address-book formats.) The services automatically mail invitations which embed URLs that lead back to the shared space, in a context that enables automatic tabulation of RSVPs and that supports group discussion (e.g., a message board) for negotation of time, venue, and agenda. 28
Let's look at one of the more sophisticated implementations, TimeDance, in more detail. If I'm coordinating an event, and want to offer a choice of times, the protocol goes like this: 29
-
I propose a list of possible times to a list of invitees. Although I seed the list with email addresses, I may also opt to delegate the task of inviting others. When an invitation is configured this way, anyone can add names to the invitation -- very helpful when I want to invite people, don't know their email addresses, but suspect that others do. 30
-
TimeDance polls invitees regarding these times. Each of these polling messages contains a uniquely-coded URL so that, when you click through to the polling page on the site, it knows who you are. 31
-
Each invitee rates each proposed time as "Great" or "So-So" or "Not Good." 32
-
During the negotiation phase, the event's web page shows its status as "people are voting on times," and -- crucially -- the discussion board is available to support freeform negotiation. 33
-
When everyone has voted, TimeDance alerts me by email, passing an URL to a web page on which it has collated the results. Time slots when everyone is available show up as green lights. Any slot can be selected to display a map of all users' preferences for that slot. 34
-
TimeDance proposes a "best" time, and asks me to choose it (or another) and announce to the group. 35
-
TimeDance rebroadcasts the now-scheduled invitation and begins the RSVP phase. Again each message contains a custom URL that leads you into a personalized space. If this is a physical meeting rather than, say, a teleconferece, you'll see its location, and can view a map (if TimeDance was able to look up the address). You'll also find a link that you can use to add the event to an Outlook, Netscape, or other vCard-aware calendar. (vCard is a standard for exchanging calendar data. See the Internet Mail Consortium at http://www/pdi.org/ for more information.) 36
-
To RSVP, you announce your plans ("Attending", "Not Attending", "Not Sure"). Again, the discussion board is available so that invitees can converse. One of the things affecting your decision to attend (or not) is the list of invitees, and their intentions. If the event organizer told TimeDance to make this information available, then it does so. You'll see a summary of the number of people in each of four categories: "Attending", "Not Attending", "Not Sure", and "Not Responded Yet". And you'll see the lists of names and address associated with each of these groups. This is a really powerful feature, which enables the event coordinator (or anyone else) to communicate with each of these dynamically-maintained lists. 37
-
The event's web page (which is by default private, but can be made public) now tracks the RSVP process. It monitors who's in each category, and continues to support group discussion. 38
-
If configured to do so, TimeDance will remind non-responders to respond, and will remind confirmed attendees to attend. 39
TimeDance is an outstanding example of Internet groupware circa 2000. Here are the reasons that make it so: 40
- Runs as a service.
There's no software to install; users simply bookmark the application. 41
- Has a low activation threshold.
An event coordinator has to register with the service, but once registered can create a new invitation with very little effort. Invitees need not even register; anyone who's invited can vote, discuss, and RSVP. 42
- Uses, but does not abuse, email.
A lot of the pain felt by email users results from the failure of messaging protocols to regard personal email as a priority communication channel. TimeDance laudably sends email on a strictly "need to know" basis. Invitees need to receive email when polled for a time, or when asked to RSVP, or when a planned time changes. But not when someone RSVPs, or posts a message to the board. Quite a lot of messaging can occur within TimeDance, but it's confined to the event's shared space where it belongs. 43
- Is a practical and effective web/email hybrid.
Messaging is a fundamental activity that, by rights, ought to be supported by a platform as fully customizable and programmable as the web browser. Unfortately email infrastructure is not (yet) that flexible. So today's Internet groupware often resorts to an awkward mixture of email for communication, and the web for application features not possible (or at any rate, not universally supported) in email clients. TimeDance strikes the right balance. It expects that your mail program will auto-activate (that is, make clickable) the URL it sends you, and it intelligently keeps the URL short enough to avoid the line-breaking that ruins this effect. But in case of a text-only reader such as pine, you can easily capture the URL and transfer it to a browser. 44
- Automates key administrative chores.
Polling for open time slots, collating RSVPs, and setting up a message board plus multiple mailing lists are activities that can eat up more of a highly-paid scientist's time than he or she cares to admit. At the level of use for which TimeDance is appropriate -- say, for events involving more than two or three people, fewer than fifty or one hundred -- it automates these things rather nicely. 45
- Does "context assembly"
When conventional email is the medium for event coordination, everybody has to keep track of everything related to the event -- the invitation itself, related documents such as maps, discussion messages. Email filtering can be used to funnel the message traffic into a designated inbox folder, but not everyone can or will go to the trouble. Unless the email is archived and web-visible, anyone who joins the list late will have missed the early discussion. 46
There's an urgent (if largely unarticulated) need for software to help us assemble all these bits of information into a meaningful context. Lacking such software, we enact collaborative protocols the hard way. Because our computers don't know about events as events, we do the context assembly -- keeping track of who's responded, separating event-related discussion from other discussion, remembering where we put the invitation and the map -- in our heads. This requires time and effort not only of the coordinator, but of all involved parties. A service such as TimeDance shows how things ought to work. Because it embodies a collaborative protocol, it wraps meaningful context around what would otherwise be a disparate set of documents and messages. 47
2 Group Discussion
Mailing lists are the de facto standard for group discussion conducted in written form. The advantages are clear. It's easy to create a mailing list, especially now that Web-based services such as http://www.egroups.com/ (free, advertising-supported) and http://www.lyris.net/ (commercial, but inexpensive) can handle all the server administration for you -- including list management, digest delivery, and searchable web archiving. Of course anyone can join a mailing list, using any Internet mail program. 48
But mailing lists aren't the best, or only, shared spaces for group discussion. Here are some of the problems: 49
- Mailing lists are awkward web/email hybrids
Email is distributed for delivery, but recentralized (in web archives) for navigation and search. So it's unclear what, exactly, is the shared space that list members occupy. Is it the collection of members' individual mailboxes, or the web archive, or both? Some web archives allow full participation, others support only reading and searching. 50
- Mailing lists aren't easily secured
End-to-end encryption of email, using PGP or S/MIME, is widely available. But mail encryption is poorly understood, not widely used for interpersonal mail, and logistically unworkable for mailing lists accessed by a variety of mail programs and (in archival form) by browsers. And, because the shared space created by a mailing list propagates to many hard disks, it's inherently difficult to secure. 51
- Email is not a rich medium for discourse
Within the constraints of the fixed-line-length ASCII email message, there is a very powerful tool: the URL. Most mailreaders can automatically render URLs clickable. This ability to cite rich web-based sources merely by naming them has radically expanded the expressive power of email. But email discussion only refers to such documents. It does not, in general, create them. 52
- Mailing lists don't layer information effectively
Newspaper and journal editors have for many years chanted the mantra "heads, decks, and leads." They assume that noboby has time to read everything, and that each published item must be packaged in layers. The headline tells the story in a few words; the deck (subtitle) in a sentence; the lead (abstract) in a paragraph. In some contexts there may be only enough space to display the headline; in other contexts all the elements may appear. The layered architecture componentizes the story. Publishers can then select and arrange these components so as to maximize that scarcest of resources: the attention of the reader. 53
Email, as a publishing medium, fails disastrously to afford this kind of layering. When you scan an inbox or mail archive, only the message's title -- that is, its Subject: header -- describes the message, and provides a clue as to whether or not to invest more time and effort in reading it. Unfortunately, because of habit and a longstanding problem with email threading, the titles are almost invariably used only to indicate threading. The resulting cascading Re: syndrome, which drains titles of their descriptive power, can be seen everywhere -- in your own inbox, and on countless mailing lists. Here, for example, is a typical mailing-list snapshot, from the Zope developers' list: 54
Figure 1: A snapshot of the Zope-Dev list 55
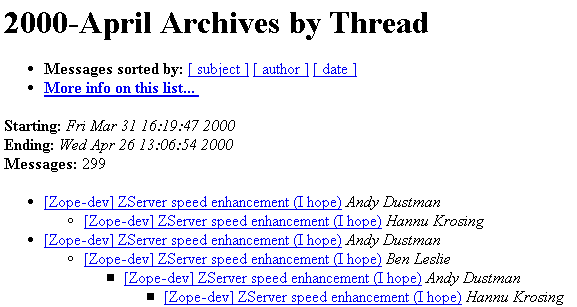
What's wrong with this picture? I can best illustrate by counter-example. Here's how I'd prefer to view this thread: 56
Figure 2: Idealized snapshot of the Zope-Dev list 57
ZServer speed enhancement (I hope) - Andy Dustman How much faster is it? - Brian Lloyd Honestly, I don't know. More improvements coming... - Andy Dustman Try apache-bench - Hannu Krosing New version now available - Andy Dustman That one's broken - Ben Leslie Oops, you're right, sorry, fix coming... - Andy Dustman Any performance tests yet? - Hannu Krosing
In light of Figure 2, Figure 1 is a disastrous information display. Its rendering of thread structure is virtually useless in the absence of descriptive message titles. Claude Shannon defined information as what you don't know -- the degree to which the next message in a series of messages surprises you. In Figure 1, the repetition of "ZServer speed enhancement (I hope)" is completely unsurprising. This sequence of message titles literally carries no information -- yet it's the only available interface to the underlying content. 58
The difference between Figure 1 and Figure 2 could not be more dramatic. In Figure 2 you can click through to the individual messages, but you don't have to click through to absorb the sense of this thread. The message titles themselves convey information; they tell a story. 59
This might seem like a pedantic point, but if you've ever spent time trying to dig information out of mailing lists (and who hasn't?), you can see that the cascading Re: syndrome is responsible for catastrophic information loss and inefficiency. Mailing lists just aren't effectively scannable. It's only practical to read lists on which traffic is sufficiently light (and valuable) to warrant sustained attention. Digests that deliver titles only are of limited use when most titles carry no meaning. Likewise web archives of mailing lists, since indexed views (and search results) are mainly lists of redundant titles. 60
We'd all like our mailboxes to look like Figure 2. But clearly, we all aren't inclined to think and act like publishers and editors. There's no simple solution to this problem. One part of the answer is sociocultural. As a species, we have very little experience inhabiting the kinds of shared spaces made possible by Internet group messaging. We are now discovering that verbal pollution of the information highway is as unpleasant as litter on the real highway. Just as we explain the rules of the road to high-school-aged students, we may decide that we ought to explain to these same people how to communicate concisely and effectively on the Internet. 61
Another part of the answer is technical. Our messaging software needs to understand that useful shared spaces require certain kinds of behaviors, and it needs to find ways to encourage and support those behaviors. 62
- Mailing lists often cannot thread messages properly
Mail threading organizes sets of messages by topic. One of two message headers -- References: (for email and newsgroups) or In-Reply-To: (for email) -- relates a message to one or more antecedents. Most email programs now emit one or both of these headers when replying to a message, and can use these headers to display sets of related messages in threaded fashion. But this wasn't always true, and still isn't for some email programs. So, while there in principle is no need to rely on the Subject: to relate a message to its topic, in practice the habit is almost universal. Because there are two contradictory uses of the all-important Subject: header -- to entitle a message, and to relate a message to its surrounding context -- mail programs and mail archivers are often unable to display threads properly. And in any case, as we've seen, threaded displays typically convey structure but little meaning. 63
2.1 Alternatives to mailing lists
2.1.1 NNTP newsgroups
This year, the Usenet celebrates its 20th anniversary. It's the grandfather of all groupware systems: a planetary discussion network that supports tens of thousands of virtual communities. At their best, these shared spaces enable groups of like-minded individuals to collaborate rather effectively. At their worst, they're overrun by spam, smut, and nonsense. This degradation poisons our notion of the Usenet and, what's worse, prevents us from fully understanding and exploiting some really useful, and well-established, collaborative tools -- NNTP (Net News Transfer Protocol) servers and clients. 64
We can, and probably should, re-invent the Usenet. Even when it works well -- there are, for example, many high-quality moderated Usenet groups -- its replication scheme has become terribly inefficient. Any given Usenet node receives and processes vastly more messages than anyone attached to that node will ever read. Why? When the Usenet grew up, there was no such thing as a near-universal real-time-connected data network. Replication was the only way to propagate messages worldwide over diverse and intermittently-connected networks. Today newsreaders can connect instantaneously to many different news servers, just as browsers connect to many different Web sites. 65
Let's imagine an alternative Usenet. It has the same number of virtual communities and the same number of nodes. But each node is responsible for just one or several shared spaces, not all of them. (NNTP replication might still mirror nodes to a few locations around the world, to improve local access, but the storage and processing costs of replication would be vastly reduced.) When each node processes vastly fewer messages, the focus can shift from quantity to quality. Here are some of the implications: 66
-
Messages need never expire, so each newsgroup remembers messages for years rather than days. 67
-
Because messages never expire, they define a persistent URL namespace. 68
-
An editor -- the person who today maintains the newsgroup's FAQ file -- can create views of that persistent namespace. These views can select, summarize, and annotate landmark contributions. 69
-
Search can be optimized for the characteristics of a particular newsgroup and its associated knowledge domain. 70
Whether or not the Usenet reorganizes along these lines, it's crucial to separate the idea of shared discussion space from its implementation as the Usenet. The Usenet's model of collaboration -- and its existing, proven tools and technologies -- can be redeployed on public sites, extranets, and intranets. NNTP conferencing can be a better kind of mailing list, one that supports the kinds of collaboration that the Web has so far failed to deliver. 71
NNTP servers, notably the standard UNIX INND (InterNet News Daemon), are freely available. Such servers are widely thought to require wizardry but, in fact, the only hard part is keeping the newsfeeds running. And there's no need to do that. You don't need to replicate with the Usenet in order to access to it; services such as http://www.dejanews.com/usenet/ and http://www.remarq.com/ serve up Usenet content and support Usenet interaction. Deploying news service locally -- to support non-Usenet mailing-list-like discussions -- turns out to be very easy. The news spool can be indexed, for searching, just like any collection of web pages or mail messages. Newsgroups can be password-protected just as web archives can be. It's straightforward to create secure channels for traffic flowing between a news server and a population of newsreaders. 72
For sites running Windows NT, the NNTP Service included with the NT Option Pack is an underappreciated gem. It's very easy to use, and highly functional. Little time or skill is required to set up a discussion server that accepts secure connections, supports fulltext search, can be divided into multiple zones of privacy, and can integrate with the Windows NT user directory. 73
Benefits of newsreader-based discussion
Like NNTP servers, NNTP newsreaders are underappreciated resources for collaboration. Most people know that the Microsoft and Netscape newsreaders can post plain-text messages to newsgroups, and attach binary files. But newsreaders offers some other, less widely-appreciated collaborative benefits vis-a-vis mailing lists: 74
-
Single message base, single interface.
Mailing lists are distributed, and the interface to them is multi-modal. One consequence is that a new participant who goes to a web archive to review prior discussion can't also join in that prior discussion. In the case of a newsgroup, discussion is fully available to anyone at any time, using the same mechanism for reading and writing. 75
-
Effective threading.
Newsgroups manage threaded views more effectively than mailing lists because newsreaders are more consistent in their use of the References: header. This doesn't, however, automatically solve the "cascading Re: problem." Like archived views of mailing lists, newsgroups are usefully scannable only if participants understand, and exploit, the principle of descriptive message titling. When users are so inclined, an NNTP discussion server supports the technique better than a mailing list typically can. 76
-
Rich messages.
In both the Netscape and Microsoft newsreaders you can, in a WYSIWYG manner, compose HTML that uses tables, inline images (which can be dragged and dropped into place), hyperlinks, fonts, and color. You can't do these things in Usenet postings, because many people don't run HTML-aware mail/news clients. But rich messaging can be appropriate in a collaborative environment where these tools are universally deployed. 77
Is this a gratuitous use of HTML? Is plain line-oriented ASCII text sufficient for scientific collaboration? Traditionally it has been, and first-generation HTML messaging has been admittedly almost as problematic as beneficial. For many scientific collaborators today, TeX attachments are a good-enough solution. But today's HTML email isn't the end-game for rich-text messaging. XML vocabularies such as MathML and SVG (see section 4 below) are gaining ground. Few would deny the benefit of ubiquitous messaging tools that natively understand mathematical equations and illustrations as well as rich text. As we'll see, the infrastructure needed to support such tools is emerging, and it's reasonable to expect to able to use these tools within a few years. 78
-
Secure communication.
People often worry about the level of encryption that protects their credit-card numbers when they order from an e-commerce website. The same people rarely worry about sending unencrypted confidential communication through a whole chain of SMTP email routers. We ought to be able to hold confidential discussions in secure shared spaces, and properly-configured NNTP newsgroups can meet that requirement. 79
2.1.2 QuickTopic
As useful as private (that is, non-Usenet) NNTP discussions can be, they fail to meet one of the requirements for an ideal collaborative solution. Most people can't form NNTP discussion spaces on the fly, without the help of a central authority. An innovative service, http://www.QuickTopic.com/ (formerly www.TakeItOffline.com), tackles precisely this problem. It's a web/email hybrid that creates "instant discussion spaces" each focused on a single topic 80
To use QuickTopic you visit the site, name and describe your discussion topic, and provide your email address. The site creates a discussion space, and emails you an URL referring to it. To recruit others into the discussion, you forward them this message (or just the URL). Topics are shown in a linear style without threading, but you can create a new topic and link it to an existing one to create a branching effect. 81
How private are these discussions? The documentation frankly explains: 82
Your topic at Take It Offline is just as private as its web address -- no more, no less. This address is extremly hard to guess. It's a randomly generated series of alphanumeric characters
This URL-is-the-password solution is fine for many kinds of casual use. More rigorous security protocols are of course possible. It would be easy to encrypt the web component of QuickTopic, though much harder to encrypt the email component while preserving the spontaneity that is a key strength of the system. 83
QuickTopic was designed not to replace the mailing list, but to augment it. Mailing lists, newsgroups, and web forums are best suited for long-term collaboration. These solutions tend to be too heavy, and too static, for the kinds of ad-hoc, short-lived interactions that characterize so much of our real collaborative work. In these situations we invariably use email, despite its limitations, because it comes easily to hand. Like the single-topic bulletin board associated with a TimeDance event, a QuickTopic instant discussion is ad-hoc, lightweight and disposable, yet more focused, more centralized, and more accessible than a mailing list. 84
2.1.3 Roundup and "nosy lists"
Ka-Ping Yee's Roundup (http://software-carpentry.codesourcery.com/entries/track/Roundup/Roundup.html), an entry in the Software Carpentry project's tracking category, proposes a mechanism for single-topic, ad-hoc discussion called the "nosy list," which works like this: 85
New items are always submitted by sending an e-mail message to Roundup. The "Subject:" field becomes the description of the new item. The message is saved in the mail spool of the new item, and copied to the list of all participants so everyone knows that a new item has been added. The new item's nosy list initially contains the submitter. 86
All e-mail messages sent by Roundup have their "Reply-To:" field set to Roundup's address, and have the item's number in the "Subject:" field. Thus, any replies to the initial announcement and subsequent threads are all received by Roundup. Roundup notes the item number in the "Subject:" field of each incoming message and appends the message to the appropriate spool. 87
Any incoming e-mail tagged with an item number is copied to all the people on the item's nosy list, and any users found in the "From:", "To:", or "Cc:" fields are automatically added to the nosy list. Whenever a user edits an item's properties in the Web interface, they are also added to the nosy list. 88
The effect is like each item having its own little mailing list, except that no one ever has to worry about subscribing to anything. Indicating interest in an issue is sufficient, and if you want to bring someone new into the conversation, all you need to do is Cc: a message to them. It turns out that no one ever has to worry about unsubscribing, either: the nosy lists are so specific in scope that the conversation tends to die down by itself when the issue is resolved or people no longer find it sufficiently important. 89
Using many small, specific mailing lists results in much more effective communication than one big list. Taking away the effort of subscribing and unsubscribing gives these lists the "feel" of being cheap and disposable. 90
The transparent capture of the mail spool attached to each issue also yields a nice knowledge repository over time. 91
This strategy is powerful because it leverages, and adds value to, existing tools and habits. Messaging, in this system, occurs within a well-defined context -- a specific project, a specific issue related to that project. Like TimeDance, Roundup proposes to keep track of context so users don't have to. 92
2.1.4 WikiWiki tools
Threaded messaging isn't the only model for online discussion. A popular alternative is WikiWiki (Hawaiian for "fast"), a freeform collaboration tool that prefers hypertextual structure to thread structure. The original WikiWiki, a collaboration among programmers that's still ongoing at the Portland Pattern Repository (http://www.c2.com/cgi/wiki?WelcomeVisitors) is a radical experiment: a collection of online documents that are always editable by everyone. 93
There are two key features of the Wiki editing environment: 94
-
New documents are automatically conjured into existence. 95
While mailing-list messages can refer to existing Web content (by citing URLs), they cannot, in general, create new Web content. In the Wiki environment, specially-written WikiNames -- which are just mixed-case, run-together phrases -- support automatic hypertext authoring. If I type the phrase "BibliographicalReferences" in a Wiki page, it will be rendered initially like this: 96
BibliographicalReferences?
Now the phrase is an invitation to create a new document of that name. Anyone can create that document by clicking the linked question mark and typing something into the editor. Once that's done, the phrase "BibliographicalReferences" will be rendered, in all pages belonging to this Wiki collection, like so: 97
BibliographicalReferences
Like URLs in email messages, these WikiNames are automatically rendered as clickable links to Web pages. But here, the process of creating the document addressed by the link has been automated. 98
-
HTML composition is simplified. 99
What can you type on your newly-created Wiki page? Here are some examples: 100
Figure 3: Wiki formatting 101
you type Wiki renders 1 *list item 1 *indented list item a *indented list item b *list item 22 This non-indented text renders in a proportional font. Now use indentation to introduce a monospaced code example:
sillyFunction(arg1,arg2)
{ return 0; } Back to normal font.This non-indented text renders in a proportional font. Now use indentation to introduce a monospaced code example: 105
sillyFunction(arg1,arg2) { return 0; }Back to normal font. 106
Constructs that are easy to type in a line-oriented text editor (such as a browser's <TEXTAREA> widget) are automatically recognized and transformed into corresponding HTML markup. 107
Wiki doesn't really do away with markup, it just simplifies it. In the first example above, the rule for lists is to type a tab plus an asterisk for a first-level item, two tabs plus an asterisk for a second-level item, and so on. In the second example, leading space tells the formatter to render code (monospaced font, line-oriented) rather than text (proportional font, paragraph-oriented). 108
How important is this kind of simplified markup? In the long run, it will likely be supplanted by WYSIWYG tools. Meanwhile, many people seem to find it useful. 109
2.1.5 Wiki clones
The original Wiki spawned a slew of derivatives. For example, if you're running a Zope site, you can install ZWiki, which enables Zope to host one or more Wiki webs. Another variant, called TWiki, addresses one of the concerns about classic Wiki, which is that its egalitarian "edit every page" philosophy leaves no change log. TWiki includes powerful revision support. Every change leaves a footprint, and you can follow these easily and effectively. 110
2.2 Review of group messaging options
Mailing lists will not, and should not, go away. They serve a vital purpose. But the old adage is relevant here: when the only tool you have is a hammer, every problem starts to look like a nail. For many modes of collaboration, the conventional mailing list is not the appropriate tool. Which alternative is best? That depends sensitively on a combination of variables. The technical characteristics of newsgroups, Wikis, and other alternatives will influence the outcome, but so will the dynamics of the groups doing the collaborating. Some groups find Wikis baffling; others take naturally to them. There isn't (yet) a single compelling strategy for next-generation group messaging on the Internet. But there are options that make group messaging -- for some groups, for specific purposes -- a more productive and useful exercise. 111
3 Broadcasting and Monitoring News
The e-print archive at www.arxiv.org has dramatically changed the way physicists publicize, and track, the literature in their fields of interest. Other scientific communities regard the archive as a bold experiment that will likely influence their own practices. Meanwhile, as the archive continues to grow in a linear fashion, physicists are starting to face some of the same information-overload problems that characterize the Web in general. On a recent Tuesday, there were 36 new papers in just one of the physics archive's 12 divisions, astrophysics. Can astrophysicists read 36 papers a day? Should they try? Clearly not. A user of the physics archive will scan the list, prioritize it based on interest in topic and familiarity with authors, read selectively, and perhaps transmit items of interest to colleagues. 112
Every web user engages daily in this process of information refinement. Many share their results -- that is, URLs with annotations -- in the form of FYI ("For Your Information") emails. Some also share their results on personal "links" pages. And a few employ a new tactic called weblogging. A weblog is really just another kind of annotated links page, typically in the form of a daily Web diary that filters and reacts to Web information flow according to personal and/or professional interests. 113
The current weblog craze is, in all likelihood, a passing fad. If you visit Blogger (http://www.blogger.com), a portal site that aggregates over 1000 weblogs, you may conclude that this form of communication has already suffered the same fate that befell the Usenet. One "blogger" (short for "weblogger") recently complained: 114
There was once a hope that the weblog could become a powerful tool for reaching out and connecting with the world. Instead, it has become a powerful tool for self-gratification and self-absorption.
But underlying the weblogging movement are two technological trends -- RSS headline syndication, and pushbutton Web publishing -- that lay the groundwork for better ways to publicize, and monitor, the activities of professional groups. 115
3.1 RSS headline syndication
RSS (Rich Site Summary) is an XML vocabulary for representing annotated links. It debuted in 1999 as the underpinning of my.netscape.com, a service that aggregates news "channels" that are "broadcast" by its users. Earlier, in 1995, the PointCast Network (now discontinued) had pioneered this idea. But publishing a PointCast channel was a complex process. As a result its news network was exploited mainly by existing publishing organizations, and ultimately failed. 116
My Netscape made the process radically simpler. Anyone could publish a channel by posting a simple XML file to a Web server, and registering that file with the service. Users of the service can then personalize their My Netscape start pages by selecting from the available channels. Here's what that start page can look like: 117
Figure 4: Monitoring RSS channels in My Netscape 118

The center column displays channels from major news publishers. The left and right columns display boutique channels run by smaller publishers, project teams, and even individuals. In this example, these channels reflect my own interests -- software and networking. There are as yet few channels devoted to scientific themes, but such channels easily can, certainly should, and probably will emerge. 119
If RSS channels could appear only on My Netscape, the mechanism would be of limited value. But there's more to the story. RSS has caught on as a standard. Many sites syndicate RSS content, by sourcing channels in XML format and rendering them as HTML. And there are several sites -- besides My Netscape -- that aggregate RSS feeds, notably UserLand Software's My UserLand (http://my.userland.com) and O'Reilly and Associates' Meerkat (http://meerkat.oreillynet.com). 120
UserLand's principal, Dave Winer, wears two hats. As a journalist, he has for years published technology news in the form of an email newsletter and a related website, Scripting News (http://www.scripting.com). In 1997, Winer began offering Scripting News in an XML format suitable for syndication. The idea was that, given a regular and predictable format for headlines and blurbs, other sites wanting to carry a Scripting News feed could easily syndicate the content -- that is, scoop up the XML, and retransmit it as HTML tailored to their own presentation styles. 121
As a software developer, Winer has evolved his product -- called Frontier -- from a Macintosh scripting language into a cross-platform (Windows/Mac-based) Internet publishing and content-management system known as Manila. It is, among other things, a channel-authoring tool. Manila can automatically make the content that it manages available in RSS format for syndication. 122
The O'Reilly Network's Meerkat is an "open wire service" that demonstrates the emergent properties of RSS syndication. Meerkat watches channels listed in two RSS registries -- one at UserLand, one at xmlTree (http://www.xmltree.com). On the union of these two registries (which are partly overlapping, partly distinct), Meerkat performs a selection. It chooses just those "technology/computer/geek" channels relevant to the O'Reilly Network's audience. Then it categorizes these channels so that a Meerkat user can make a single selection -- say, Python -- in order to view headlines and blurbs from a half-dozen Python-related channels. 123
Behind the scenes, the editors and writers at the O'Reilly Network -- which is itself an informational site for software developers and Internet technologists -- use Meerkat to track their individual beats. They select interesting items, add additional analysis to them, and republish them along with the site's original content. In parallel, they maintain Manila weblogs where, as columnists, they can deliver less formal, and more personal, summary and analysis. These weblogs, thanks to Manila's automatic syndication, flow back out onto the RSS wire. See, for example, Edd Dumbill's weblog (http://weblogs.oreillynet.com/edd/). 124
All this adds up to a new kind of information ecology inhabited by RSS authors, sites that syndicate RSS content, and services that aggregate, select, refine, and republish RSS content. In the most populous niche of this ecology -- the "technology/computer/geek" space occupied by the likes of UserLand and Meerkat -- the publication and assimilation of news is radically simplified and accelerated. News, in this realm, takes on a broader-than-usual meaning. Anything that can be referenced with a URL is fair game. That includes announcements, feature stories, opinions, and analysis published on conventional media sites. But it can equally include entries from weblogs that report on very narrow and specific fields of interest. Typically, such weblogs are themselves aggregators of many sources of information. One of the most intriguing new roles that has emerged is what might be called a list guide. By that I mean a specialist in a field who monitors its mailing list or newsgroup, and draws attention to significant items -- often packaged with a bit of analysis. In this way interested people who lack the time and/or expertise to process the raw feeds can, nevertheless, keep in touch with developments in related, or even distant, disciplines. 125
3.2 Pushbutton web publishing
Although HTML is a far simpler markup language than, say, TeX, today's Web is biased heavily toward consuming content, and offers little support for producing it. The Web, in its current incarnation, is a library in which we read, not a bulletin board on which we scribble. The Internet application that we do use for scribbling -- endlessly, prolifically -- is email. But while email can (and often does) become Web content, it's never first-class Web content. 126
Lately there is movement on a number of fronts to reclaim the two-way, read/write architecture that was the Web's original conception. Part of the story is a new protocol called WebDAV (Web-based Distributed Authoring and Versioning, http://www.webdav.org/, also known simply as DAV), which enables client applications to store documents directly on a DAV-aware Web server, lock and unlock the documents, and query or set their properties. DAV-aware servers include Apache (with the mod_dav module), Microsoft's Internet Information Server version 5, and Digital Creations' Zope. DAV-aware clients include the Microsoft Office apps and, more recently, Adobe's Go Live, a Web authoring and content-management tool. 127
3.2.1 From FTP to WebDAV
You can think of WebDAV, in its current form, as a "better FTP" that integrates directly into applications, making "save to the Web" a pushbutton affair. It supports locking, and deals more powerfully than FTP with moving and copying collections of files. The DAV FAQ notes these additional benefits: 128
Since DAV works over HTTP, you get all the benefits of HTTP that FTP cannot provide. For example: strong authentication, encryption, proxy support, and caching. It is true that you can get some of this through SSH, but the HTTP infrastructure is much more widely deployed than SSH. Further, SSH does not have the wide complement of tools, development libraries, and applications that HTTP does.
FTP is deeply entrenched and still overwhelmingly dominant, but DAV is maturing and will very likely displace FTP over time. Less clear, at this moment, is what will come of the versioning and configuration management features (http://www.webdav.org/deltav/goals/draft-ietf-webdav-version-goals-01.txt) proposed for DAV. 129
3.2.2 Manila
Manila's approach to the two-way Web proceeds from the assumption that, while DAV-enabled writing and content-management tools are desirable, they are not strictly necessary. The basic browser, backed by conventional Web-server software, can empower groups to collaborate and to publish their collaborations on the Web. 130
To that end Manila, among other things, is a Web-based discussion system. Every story or news item posted to a Manila site can be a launching point for threaded discussion -- which can occur out in the open, visible to all site visitors, or privately, visible only to members of the site. 131
Manila supports pushbutton web publishing in a number of ways: 132
-
Instant startup. UserLand offers a free service -- www.EditThisPage.com -- so that anyone can launch and run a collaborative weblog that publishes news and discussion in some area of interest, and integrates with the RSS news network. You can, of course, buy Manila/Frontier and deploy it on your own Internet or intranet site, but EditThisPage.com delivers instant gratification. 133
-
Live editing. A site operator can use the Edit link that appears on every page to fetch and modify the page in a browser form. There's limited support for Wiki-like automatic formatting and, in MSIE, a simple interactive formatter helps authors apply styles to selected ranges of text. In general, though, Manila doesn't pretend to be a full-blown Web authoring environment. Its goal is to move the kind of simple writing that we do in email into the realm of managed, and syndicated, websites. 134
-
Publication workflow. A Manila site embodies a specific groupware protocol -- that of a newspaper or journal. It supports the notion of a managing editor, working with a team of contributing editors, to produce a stream of stories that are developed internally, discussed, edited, and then released to the public. 135
-
Spontaneous citation. One of the most fundamental acts of Internet collaboration is the "FYI email" -- a message that cites, or attaches, an interesting Web document. It's incredibly valuable to be able to do this spontaneously, as email permits. But there are also some severe drawbacks. The FYI email targets only the specified recipients. It appears in their message flow -- too often, as clutter -- and then scrolls off the event horizon. It doesn't, in general, create a public document that can be found by other people, at other times, working in different contexts. With Manila, the impulse behind a spontaneous FYI email can -- using a small helper application called Manila Express -- be expressed as a spontaneous act of web publishing. Consider this example: 136
Figure 5: Manila Express 137
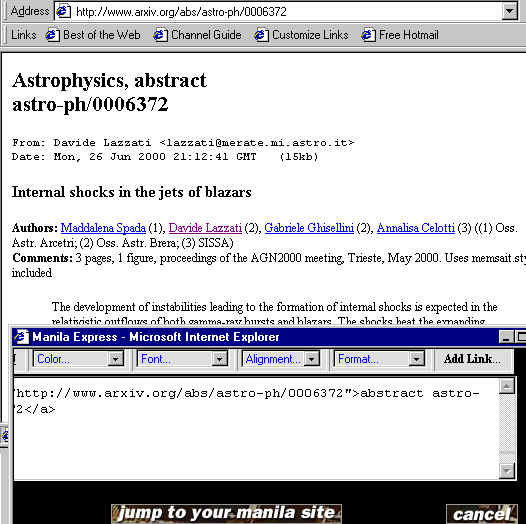
Here, while viewing an astrophysics abstract in MSIE, I've launched Manila Express (from MSIE's right-click-accessible popup menu). It has loaded the URL of the abstract into its editing window, and I've begun to write an annotation for the cited paper. When I click the Post button, the URL-plus-annotation is added to my Manila weblog -- and to its RSS channel. Thus, in a single stroke, I've accomplished three collaborative goals. First, I've alerted anyone who visits my weblog to the existence of this paper, and my explanation of its importance. Second, I've enabled the paper, and my analysis of it, to form the seed of a threaded discussion. Third, I've broadcast my citation-plus-analysis to the RSS network, so that people not directly tuned into my weblog can nevertheless discover this item. How? Let's turn our attention from the realm of RSS authoring and publishing to the realm of RSS aggregation, viewing, and searching. 138
3.2.3 Meerkat
Meerkat is nominally an RSS aggregator and viewer. It fetches RSS channels from multiple registries, eliminates duplication, and stores the resulting set of items in a database. Through its Web interface you can query that database. In this example, Meerkat reports all items for the last 30 days, from all channels grouped in the SCIENCE category, that mention the term "black hole": 139
Figure 6: Meerkat 140
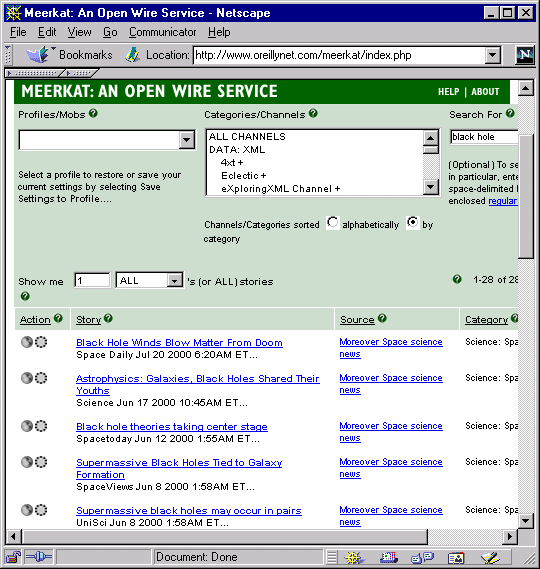
But Meerkat's inventor, Rael Dornfest, has also made it into tool that simplifies publishing, as well as viewing, sets of RSS items. Registered users can define two kinds of named collections. A profile is a stored query. So for example, the Meerkat URL http://meerkat.oreillynet.com/?p=739 names a query that asks: "Show me all the items from Jon Udell's channel." A mob is an arbitrary collection of items. A user can define such a collection, give it a name such as "BlackHole," then assign items from any channel to it by clicking one of the item's circular icons. Like profiles, mobs are represented by URLs that can be shared in email, or published on websites. 141
For the Meerkat user, managing these stored queries and named collections is a point-and-click affair. But suppose you want to republish these views of the RSS news flow? Meerkat supports a number of interfaces that make it easy to repurpose the content it manages. You can, for example, ask Meerkat to produce output in the same RSS format that it consumes. In this mode, Meerkat runs as a pure filter -- one of potentially many phases in an information-refinement pipeline. This is a crucial point. Applications and services that both consume and produce XML are, automatically, reusable components that can be combined and recombined to create novel effects. There is not likely to be a single "killer app" in the realm of Internet groupware. Rather, there will be a "killer infrastructure" -- based on universal representation of data in XML -- that enables a whole class of specialized, ad-hoc applications in the same way that the UNIX pipeline did. 142
Alternatively, to present a Meerkat view on a Web page, you can instead ask Meerkat to render the XML into HTML. This XML-to-HTML transformation is necessary because not all browsers can render XML directly. But we're nearing the end of that era. Internet Explorer can already do it. So can the new Mozilla. 143
3.3 The importance of RSS technology
RSS is widely regarded as one of the more successful applications of XML. One reason, undoubtedly, is that it's a very simple application of XML. I've focused here on tools that automate the creation and use of RSS channels but, in truth, these tools are optional. Here's an item from my own channel: 144
<item> <title> Talk | MathML </title> <link>http://www.byte.com/nntp/applications?comment_id=7158#thread</link> <description> There appears to be strong progress on the MathML front. The w3c working draft (version 2) is in last call, and it is one of more beautifully written documents of its type that I've ever seen. </description> </item>
As with HTML itself, RSS is easily written by hand. That makes it equally easy to create tools that transform a variety of other formats into RSS. Unlike HTML, RSS content can be parsed in a simple and reliable way by any XML-aware scripting language. That makes it easy to create tools, like Meerkat, that capture, organize, and enhance RSS flows. 145
The value of the RSS network depends, of course, on the nature and quality of news flowing through it. In the "technology/computer/geek" community where RSS evolved, it has become a powerful, well-established, and comprehensive system for focusing attention on leading-edge developments. Tools like Manila and Meerkat are rapidly evolving in ways that can bring the benefits of that system to other communities in need of them, including many scientific communities. 146
Information overload is a severe problem, and there isn't a single best solution. Weblogs syndicated on the RSS network are no more inherently immune to signal degradation than the Usenet was. XML, in and of itself, doesn't change anything either. What is new, and hopeful, is the notion of a standard format for content syndication. That standard is enabling a new class of information-refinement tools. These tools in turn enable people to search, select, annotate, and reorganize the Web's chaotic flow more easily and more effectively than is otherwise possible. 147
4 Scientific Publishing
For scientific publishing, there isn't yet an acceptable alternative to TeX/LaTeX, Word, and FrameMaker. But better solutions are in view, and they all revolve around standard representation of content in XML. Admittedly, while the publishing industry has embraced XML in principle as the universal format for content, there is not yet in practice much writing of XML. When Web Review (http://www.webreview.com/) asked its audience of Web-savvy authors and developers how many were writing XML, more than half responded "Don't know where to begin," and only 15% said "Use regularly" (http://webreview.com/wr/pub/2000/06/23/poll/results.html). 148
Few could argue against the inherent benefits of an XML-aware writing tool. Consider, for example, why TeX is popular. Math typesetting is part of the reason, but TeX's ability to transform bibliographic markup into the various formats required by journals is another key strength. 149
Who wouldn't want a WYSIWYG XML editor that can: 150
-
work interactively with text, equations, and illustrations 151
-
understand and enforce required formats 152
-
guarantee easy and automatic repurposing of content 153
-
work with material that's always editable, yet always Web-ready 154
MS Word doesn't do these things yet, but Microsoft's June 2000 announcement of its XML-based ".NET platorm" (http://www.microsoft.com/presspass/topics/f2k/presskit.asp) suggests that Word inevitably will. Meanwhile, other vendors are charging ahead. In 1999, SoftQuad (http://www.softquad.com/) broke new ground with the first affordable WYSIWYG XML editor, XMetaL. Previously, the market for such tools was dominated by multi-thousand-dollar SGML tools, retrofitted with XML capability, from companies such as ArborText (http://www.arbortext.com) and Inso (http://www.inso.com). XMetaL, a $500 Window desktop application, delivers many of the benefits of the high-end tools. 155
In XMetaL's WYSIWYG mode, you write as with any word processor. Display of the XML content is controlled by a CSS stylesheet. Everything you write in XMetaL is also validated -- interactively -- against a DTD (document type definition). Given a DTD that describes the elements that can occur in a scientific paper, and the sequence and patterns in which these elements can occur, XMetaL helps you to create a conforming document, prompting with the elements that are valid in a given context, much as a programmer's editor might prompt for the arguments that it is legal to pass to a function. 156
Like the new generation of browsers (MSIE 5, Mozilla), XMetaL is also a toolkit for developing content-oriented applications. It provides a W3C Document Object Model (DOM) interface to the content that it manages, and it wraps a universal scripting interface around that DOM. Because XMetaL is an ActiveX scripting host, scripts can be written in any compliant scripting language including VBScript, JavaScript, Perl, or Python. Such scripts can be used, among other things, to create "wizards" that help users write to DTD-prescribed formats. And this is the crucial point. A DTD that defines bibliographies for scientific papers is, by itself, just a passive set of rules to be learned and followed. People won't embrace XML-oriented writing tools if they're expected to replace one set of passive rules for another. What people will embrace are tools that help them enact required protocols. Bibliographic citation is just one example of such a protocol. Understood properly, virtually every act of written communication -- a software bug report, a comment on a draft of a paper, an email message requesting action on a certain item by a certain date -- is located, conceptually, within a rule-based protocol. 157
The future of Internet-based collaboration depends, to a very great extent, on the ability of software to embody these protocols. In this regard, XML's role as a universal storage and exchange format is only half of the story. Equally vital is its ability to express, and enforce, the rules of engagement that govern all collaboration. It can't meet that objective, though, until it's woven into the fabric of everyday life. Structured writing can't, and won't, continue to be a specialized activity. It needs to flow automatically from normal use of the frontline applications -- word processors, email clients -- that capture most of what we say, and produce most of what we know. 158
The bad news is that infrastructure change on this order of magnitude can't happen quickly. The good news, though, is that there is now general consensus as to how to accomplish the change, and much demonstrable recent progress. To illustrate that concretely, let's consider how two datatypes central to scientific collaboration -- equations and charts -- are being woven into the fabric of the emerging two-way Web. 159
4.1 Math on the Web
For scientists it's painfully ironic that the Web, invented expressly to help them collaborate, still lacks strong support for one of the primary forms of scientific discourse: mathematical equations. As a result, mathematical content is typically delivered on the Web in one of a number of unsatisfactory ways. Equations can be viewed as bitmapped images included within HTML files, or within PDF files, or in a Java viewer (e.g., WebEQ), or in a free or commercial plug-in (e.g., LiveMath, IBM techExplorer). In all of these cases, however, equations end up as foreign data types. Things you can't do with this foreign content include: 160
-
Write equations using conventional HTML authoring tools. 161
-
Cut and paste them easily, if at all. 162
-
Search them and their surrounding text at the same time. 163
-
Style them along with surrounding text. 164
-
Attach hyperlink sources and targets to them. 165
-
Attach scripted behavior to them. 166
For years there's been discussion of a more Web-native way to create and display math. These efforts are now beginning to bear fruit. A second version of the W3C's working draft of MathML (http://www.w3.org/TR/2000/WD-MathML2-20000328/), a math-oriented application of XML, is in the "last call" stage, and both commercial vendors and the open source community are lining up in support of it. 167
Why the slow start? Pre-existing tools, notably Donald Knuth's TeX -- a superlative and widely-used system for math typesetting and composition -- weren't easy to integrate with the Web's original model. Only recently has XML become firmly established as a general strategy for extending the Web. It's one thing to embed a foreign chunk of math into an HTML page, like this: 168
Figure 7: Foreign math 169
<p> As you can see from this example: </p> <embed src="SomeMathPlugin"> <p> , the result... </p> |
It's something else again to weave the math right into the fabric of the page, like this: 170
Figure 8: Native math 171
<p>
As you can see from this example:
<math>
<mfrac style="font-size: 14pt">
<msqrt>
<mi href="/definitions#k" xml:link="simple">k</mi>
</msqrt>
<msup>
<mi>m</mi>
<mn>2</mn>
</msup>
</mfrac>
</math>
, the result...
</p>
|
Note the style attribute attached to the <mfrac> element. Note also how the term k links to an address (/definitions#k), so that the reader of this equation can click on the k to find out more about it. This is the kind of deep and fluid integration that the phrase "math for the Web" conjures in our imaginations. And it's now tantalizingly close to being real. I didn't just pull the markup in Figure 8 out of thin air. I captured it from the View Source window of Amaya (http://www.w3.org/Amaya), the W3C's testbed browser. Here's Amaya displaying the equation in Figure 8: 172
Figure 9: Amaya rendering MathML 173
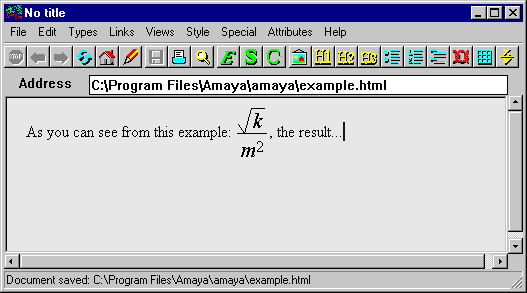
Clearly Amaya is rendering the font style attribute attached to the fraction. But a couple of things aren't obvious in this screen shot. First, the hyperlink wrapped around the k really is there, and really works. Second, Amaya isn't just a viewer, it's an editor. Everything that it's displaying -- the text and the equation -- is also live for editing. 174
In the case of Amaya, such editing occurs in WYSIWYG mode. But an effective tool might as easily accept TeX markup, such as many scientists are trained to write. The point is not how the web version of a document is edited, but that it can be edited in a direct way. 175
Currently at version 3.2, Amaya isn't nearly stable enough or complete enough for real work, but it's an intoxicating glimpse of the way things ought to be. In addition to MathML, incidentally, its XHTML capabilities are noteworthy. You can use its "Save as XHTML" feature to automate the grunge work of transforming a file of normal HTML into a file of well-formed and more maintainable XHTML. 176
4.1.1 Beyond compound documents
Since the advent of OLE and OpenDoc, we've aspired to "document-centric" computing. We no longer want GUI windows to represent monolithic documents backed by single applications. Rather, we want them to contain heterogenous documents that represent task-focused activities and that are supported by a suite of cooperating applications. While technologies like OLE embedding enabled a window to contain a mixture of textual, graphical, and tabular components, each of these was still backed by an application that represented the data in its own proprietary way. You could mix the components on the page, and pass data among them using DDE or the clipboard, but you couldn't really blend them together. The model was more like Figure 7 than like Figure 8. 177
What justifies all the XML hype is that it promises to fundamentally unify the representation of data. When a page contains a chunk of XHTML text, and a chunk of MathML equations, and a chunk of SVG graphics, it isn't just a canvas with three things stuck onto it. It's a fabric woven from three kinds of threads. Textual elements belonging to each thread are subject to the same search and styling mechanisms. Every element is part of the DOM (document object model) and, as such, available to controlling scripts. 178
To understand why universal data representation matters so much, ask yourself: "Why did UNIX succeed?" The stock answer is that UNIX invented the idea of software components that could easily be arranged in many useful ways. But what made that possible? The components agreed on way of representing data as line-oriented text made of tokens delimited by whitespace. That enabled a host of glue technologies -- the shells, sed, awk, Perl. We're now seeing a new generation of glue technologies that agree on the much richer data representation afforded by XML. For interconnecting Web services, these XML-over-HTTP protocols have rapidly become the de facto standard. The next frontier will be Web applications that move beyond Figure 7's compound document model, and agree on standard XML data representation that allows different datatypes to blend and interact. 179
4.1.2 Mozilla and MathML
The Mozilla project is taking MathML very seriously. The MathML support isn't in the standard build yet, but if you want to try it you can download a MathML-enabled version of Mozilla (http://www.mozilla.org/projects/seamonkey/release-notes/). Unlike Amaya, Mozilla isn't (yet) a MathML editor, only a viewer, but as such it's making terrific progress. Interestingly, as noted in a progress report (http://www.mozilla.org/projects/mathml/update.html) by Roger Sidje, a key (and non-Netscape-employed) contributor, MathML is the first major Mozilla component driven entirely by outside interests unaligned with Netscape's commercial priorities. 180
The initial goal of the Mozilla MathML effort is to leverage -- and stress-test -- the browser's new layout engine ("Gecko"). To that end, it will focus on presentation markup as opposed to content markup. What's the difference? The former says things like "put a row of elements here, then underneath, a box containing these elements." The latter says things like "apply this operation to these subexpressions." The W3C's working draft explains: 181
Both content and presentation tags are necessary in order to provide the full expressive capability one would expect in a mathematical markup language. Often the same mathematical notation is used to represent several completely different concepts. For example, the notation xi may be intended (in polynomial algebra) as the i-th power of the variable x, or as the i-th component of a vector x (in tensor calculus). In other cases, the same mathematical concept may be displayed in one of various notations. For instance, the factorial of a number might be expressed with an exclamation mark, a Gamma function, or a Pochhammer symbol. 182
Thus the same notation may represent several mathematical ideas, and, conversely, the same mathematical idea often has several notations. In order to provide authors with the ability to precisely control notation while at the same time encoding meanings in a machine-readable way, both content and presentation markup are needed. 183
There are deep subtleties here. Sometimes presentation markup embeds within content markup so that the application gets hints about how to render equations; sometimes content markup embeds within presentation markup, to specify which mathematical meaning is intended; sometimes the two occur in parallel, when the relationship between content and presentation cannot easily be inferred. Even for specialized math software, mastering these subtleties will take a long time. So how can Mozilla compete? It doesn't have to. The purpose of its MathML support is to help people communicate mathematically on the Web, in accordance with this excellent mission statement from the W3C: 184
In practical terms, the observation that mathematics on the Web should provide for both specialized and general needs naturally leads to the idea of a layered architecture. One layer consists of powerful, general software tools exchanging, processing and rendering suitably encoded mathematical data. A second layer consists of specialized software tools, aimed at specific user groups, which are capable of easily generating encoded mathematical data which can then be shared with a particular audience. 185
MathML is designed to provide the encoding of mathematical information for the bottom, more general layer in a two-layer architecture. It is intended to encode complex notational and semantic structure in an explicit, regular, and easy-to-process way for renderers, searching and indexing software, and other mathematical applications. 186
In light of this goal, consider this screenshot posted to news://news.mozilla.org/netscape.public.mozilla.mathml, which illustrates the composition of an email message that intermixes textual and mathematical content: 187
{kind=link}
Figure 10: MathML-enabled Mozilla 188
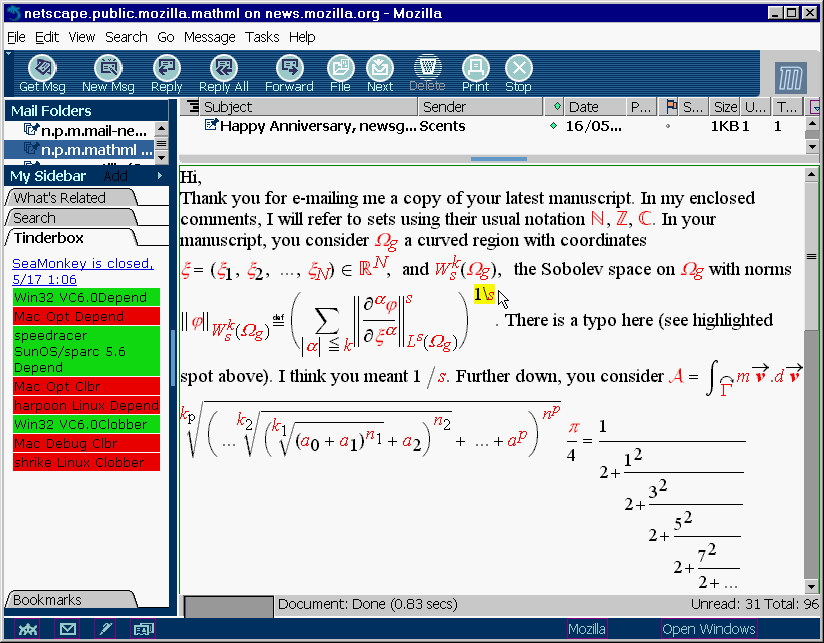
Now that's a picture of the way things ought to be! And not just for math on the Web, but for all kinds of content. Scientific collaboration is an ongoing discourse involving text, graphics, math, and other datatypes. Why shouldn't email, the medium through which so much of that discourse is conducted, natively understand those datatypes? Clearly it should. This inspiring glimpse of the future reminds us that the days of the 65-character-per-line ASCII-art email message are, inevitably, numbered. 189
4.2 SVG: PostScript for the Web
When scientific papers written in TeX include charts and illustrations, these are embedded as foreign (typically, PostScript) objects in the TeX source stream. Once rendered to PDF, as is now done on demand for papers posted to the physics e-print archive at www.arxiv.org, the text, equations, and illustrations appear to merge into a single presentation. But PDF files are not first-class citizens in the Web environment. Like PostScript objects embedded in TeX files, PDF files are themselves foreign objects that do not integrate natively with the "universal canvas" of the web. 190
Microsoft coined the term "universal canvas" when it announced its next-generation platform, .NET. The term connotes a single viewing and editing surface on which heterogenous datatypes fluidly interact. These datatypes are supported by a range of specialized services for text, equations, and illustrations. But, since everything shares a common XML representation, there are also common services for search and annotation. 191
Consider this simple bar chart: 192
Figure 11: Simple chart 193

To include this chart in a printed report, you need to rasterize the image. The same rasterized image can be embedded in an online, HTML-based version of the report, but: 194
-
You can't search or select the text in the chart in the same way that you search or select the text of the report that embeds the chart. 195
-
You can't redraw the chart to show more (or less) detail. That's not an issue in this simple case, but for complex illustrations you'd like to have use of the information in a scalable vector format, not a rasterized (bitmapped) format. 196
-
You can't link from elements of the chart so that, for example, each of its datapoints leads to a page of supporting details, or to an input mechanism that collects annotations specific to that element. 197
-
You can't link to elements of the chart. In a more complex illustration, there might be several views. Ideally these should be named, and the illustration should export that namespace so that its component views can be referenced directly. 198
A PDF version of the chart, included in an online version of the report, delivers some of these capabilities. It's scalable, and can support outbound linking. But it can't support direct inbound references, and if its container is HTML it won't integrate very well with that container. 199
If HTML could handle vector graphics, it would solve these problems. In fact, HTML can do simple vector graphics, and that's how this chart was produced: 200
<H2>Current disk quota usage by team<br>(updated every hour)</H2>
<H3>Production Volume (/dev/vx/rdsk/production/vol01:)</H3>
<TABLE CELLPADDING=2>
<TR>
<TD ALIGN=RIGHT><B>MB Max</B></TD>
<TD ALIGN=RIGHT><B>MB Used</B></TD>
<TD><B></B></TD>
<TD ALIGN=RIGHT><B>% Used</B></TD>
<TD><B>Team</B></TD>
</TR>
<TR>
<TD ALIGN=RIGHT> 175104.00</TD>
<TD ALIGN=RIGHT> 101141.60</TD>
<TD>
<TABLE CELLPADDING=0 CELLSPACING=0 BORDER=0>
<TR>
<TD BGCOLOR='#003366' WIDTH=115 HEIGHT=15></TD>
<TD BGCOLOR='#CCCCCC' WIDTH=84></TD>
</TR>
</TABLE>
</TD>
<TD ALIGN=RIGHT> 57.8%</TD>
<TD>RETAIL</TD>
</TR>
Clearly HTML's primitive vector graphics can't support even pie charts, let alone plots of equations. But consensus is now emerging that SVG (Scalable Vector Graphics, http://www.w3.org/Graphics/SVG/) is ready to deliver more sophisticated vector graphics in a way that preserves the benefits of HTML's Web-native approach. Adobe has now released the 1.0 version of SVG viewer. Here's a picture of an SVG version of the same chart, viewed in MSIE with the Adobe SVG plug-in. 201
Figure 12: SVG version of chart, viewed in the Adobe plug-in 202
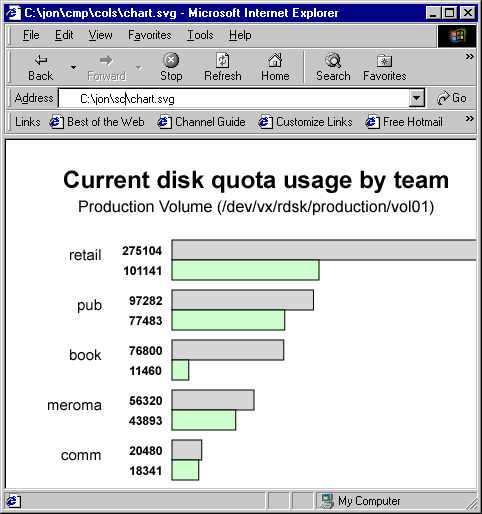
Creating the SVG version of the chart is a lot like creating the HTML version -- and that's a very good thing. As with HTML, there are all sorts of construction techniques: you can write the stuff by hand in a text editor, you can write scripts to automate parts of that process, or you can use WYSIWYG editors to build it interactively. Web developers already familiar with CSS styling and scripted, template-driven HTML construction will find themselves immediately productive with SVG. 203
To give you a sense of what's involved, I started building this SVG example in Jasc Software's Trajectory Pro (http://www.jasc.com/trj.asp), a new WYSIWYG vector-illustration tool whose native format is SVG. But anyone familiar with HTML can make a simple chart like this one, using none of SVG's advanced effects -- paths, gradients, filters -- without a WYSIWYG tool. Here's a chunk of SVG for a label and its associated pair of bars: 204
Figure 13: SVG fragment for element cluster 205
<g transform="translate(1in,100)"> <text style="text-anchor:end; font-size:15; font-family:Arial" x="0" y="20">retail</text> <rect style="stroke:#000000; fill:lightgray" x="70" y="0" width="400" height="20"/> <text style="text-anchor:end; font-family:Arial; font-weight:bold" x="60" y="15">275104</text> <rect style="stroke:#000000; fill:#ccffcc" x="70" y="20" width="147" height="20"/> <text style="text-anchor:end; font-family:Arial; font-weight:bold" x="60" y="35">101141</text> </g> |
A chunk of SVG like the one in Figure 13, whether tool-written or hand-written, wants to be parameterized so you can automatically repeat it with variations. That's a job for a script. The familiar idiom used so often to automate HTML construction -- templatize a chunk of markup, then loop through a data structure populating instances of the template -- works equally well in SVG. 206
With the Adobe viewer, you've got a true scalable vector image. You can zoom in and out, pan around, print with high fidelity. 207
Of course an SVG plug-in is no more a Web-native tool than the PDF plug-in. But native browser support for SVG is forthcoming. Here, for example, is an early look at an SVG-enabled version of Mozilla: 208
Figure 14: SVG-enabled Mozilla 209
There are also standalone SVG viewers. Java viewers include CSIRO's SVG Toolkit (http://sis.cmis.csiro.au/svg/) and IBM's SVGView (http://www.alphaworks.ibm.com/tech/svgview). Native Linux viewers include Raph Levien's Gill (http://www.levien.com/svg/) and Lauris Kaplinski's SodiPodi (http://sodipodi.sourceforge.net/). 210
In the short run, PDFs made from TeX files with embedded PostScript illustrations will continue to be widely used, and to be useful. The same is true for HTML documents that embed rasterized illustrations. But SVG (or something very like it) will prevail, because in the long run the benefits of the universal canvas are irresistable. An SVG illustration isn't just something stuck onto a Web page, it's woven right into the fabric of the page. You can search for text anywhere. You can link from SVG elements to other content. Or you can link to SVG elements from elsewhere. Like an HTML page with many named regions, a chunk of SVG can export a namespace that defines entry points to multiple views. 211
4.2.1 XML editors and the universal canvas
In a thought-provoking essay (http://www.excosoft.se/indexns.html), Jan Christian Herlitz, R&D manager for ExcoSoft, notes that a spreadsheet can be represented in XML like this: 212
<CELL id="B40">262</CELL>
Argues Jan: 213
Does this mean that Excel is an XML editor because it stores data in XML? Will today's XML editors be spreadsheet tools if they can read Excel files? The answer to both questions is an emphatic no! A spreadsheet editor must map the XML code onto a spreadsheet data structure with cells and formulas, calculate results, and present the results in the typical spreadsheet manner. 214
The next generation of editors will read and present XML-based information, whether it be paragraphs, tables, drawings, e-mails or spreadsheets. Everything will be done in one user interface. Behind the scene, different software components from different vendors will be activated to handle different parts of the information. Integration will be achieved through "styling". An element will be styled as, for example, a spreadsheet. A spreadsheet component will be fetched to calculate and present the information. As everything is basically XML, the user will experience a much simpler and more natural user interface. All types of information can be stored in one document (separate entities are not needed). Text is handled in a uniform manner. Everything can be searched. Everything can be styled. Everything can be inside everything else; an equation inside a table which is inside a drawing which is inside a spreadsheet. 215
The next generation of editors will be both editors and browsers, but they will not in a meaningful sense be XML editors. They will simply be clients! 216
Everything's converging on universal data representation in XML. We're headed beyond OLE-style embedding, into a realm where datatypes blend more intimately and where standard tools and techniques apply to heterogenous mixtures of these datatypes. SVG isn't ready for prime time yet, but it's designed to support Web-based collaboration in ways that PDF is not. 217
5 Final Recommendations
The "universal canvas" is a lovely idea that we will, let's hope, someday take for granted. But we live in the present. Although we like to think we're running on "Internet time" the tools available for collaboration change slowly, as does the culture surrounding the use of those tools. 218
Email always was, and still legitimately remains, the fundamental tool of Internet collaboration. But there is now emerging a class of Web-based services that can augment or replace email for certain kinds of collaboration, such as event scheduling (e.g., TimeDance) or discussion (e.g. QuickTopic). These services are notable both because they meet immediate practical needs, and because -- being Web-based services -- they can act as the building blocks of new, ad-hoc collaborative solutions. They are to the Web what grep and friends are to UNIX -- reusable components that can be pipelined. 219
The Web version of this report ([Final URL]) illustrates one such pipelined solution. The document's source is XML in its simplest form -- that is, HTML that observes a few conventions required for XML compliance. As such it is easily transformed into an enhanced rendering that is "instrumented" for collaboration. Here's a picture of that enhanced rendering: 220
Figure 15: Collaboratively-reviewable version of this report 221
The numbered links following each paragraph mean that each location in the document can be referred to precisely. And the actions tied to those links support collaborative review of the document. Clicking on one of the links in Figure 15 produces this form: 222
Figure 16: Form for commenting on this report 223
The form in turn posts a comment to a QuickTopic discussion space: 224
Figure 17: Discussion space for this report 225
In that discussion space, a comment refers back to the document, at the location in the document that triggered the comment. 226
Exactly how this works isn't important here. The salient points are: 227
-
It wasn't hard to arrange this effect. Well-structured content, even of the simplest kind, has emergent properties. It easily and naturally morphs into forms that support Web-based collaboration. 228
-
Any Web discussion component could support the effect. Although I've used QuickTopic here, I could as easily have used any discussion tool that can plug into what we might call a "Web pipeline." Most Web services have this property automatically, just because they are Web services, equally accessible to interactive browsers and to programmatic scripts. 229
-
The lack of XML writing tools is a critical bottleneck. The writing tools we use every day -- word processors, email composers -- capture most of the raw materials of Internet collaboration. But they don't capture the stuff, yet, as XML. It's true that for a scientist who has mastered TeX or LaTeX, the marked-up source of this report is child's play. But nobody ought to be expected to compose markup directly. Scientists should expect, and demand, that their everyday writing and messaging tools process text, equations, and illustrations in a WYSIWYG manner, and represent the stuff in a universal standard format that enables new, more granular, more accessible, and more powerful forms of collaboration. 230
-
Web services can already support better collaboration. The XML-aware writing tools we need are coming along too slowly. But much can be accomplished without them. The discussion space for this report would still be extremely useful even without the XML-enabled element-level crosslinking. There are lots of opportunities, nowadays, to move collaboration into shared spaces. Doing so can help relieve some of the problems we create for one another when we force email to carry the whole burden. 231
5.1 The two-way Web
The goal of Internet groupware should be to reclaim the original vision of the Web as a medium of collaboration. It's no accident that vision arose in a scientific milieu since the enterprise of science is so deeply rooted in collaboration. 232
This report ends with two final messages. First, we're closer to the two-way Web than we realize. Services such as TimeDance, QuickTopic, Manila, and Meerkat are already making it easier than ever to create and use shared information spaces. They aren't final solutions, but we should use them for all they're worth, and watch for new kinds of collaborative services that are emerging every day. Only by using these services in their current form will we discover, collectively, what they need to evolve into. 233
Second, the roadmap to the future is coming more sharply into focus. The first-generation Web, though remarkably powerful, is an awkward combination of many different protocols and data formats. The emerging consensus around XML, as a universal way both to interconnect services and to represent many different kinds of information, is the key to a next-generation Web that may finally start to deliver on the collaborative vision of the original. There's nothing magical about XML. It isn't pixie dust. It doesn't, in and of itself, help us collaborate. What will help is messages, documents, applications, and services that all agree on a standard way of representing data -- one that's richer than the line-oriented ASCII we've used so long and so well. That standardization is now occurring. We should welcome it, and we should demand that our tools respect and embrace it. 234