Tangled in the Threads
Jon Udell, November 2001Digital Archives
The ephemeral web finds new hope of permanence
This week I received the following query:
I was wondering if you had a copy of the article "Citrix's New Multiuser OS/2". The biblio info said you are the author and it appeared in the Jan '91 issue of BYTE.
I'd like to reference it, as I am writing an article for www.os2ezine.com on the new OS/2 client software!
Thanks, Dan Eicher
Luckily for Dan, I happen to have a few remaining copies of the BYTE CD-ROM, which happens to include the article he was looking for. Fondly remembering the piece, I posted a copy1 on my webserver. Citrix and OS/2 have long since parted ways, of course, but the company's ongoing success confirms my bullish first impression of its product a decade ago.
While it was fun to recall this blast from the past, it was also disturbing to be reminded of the fragile nature of electronic publication. Recently, I've been feeling a lot like Sisyphus trying to push a huge boulder up a hill of entropy. For example, a reader of a website that I run, www.linux-mag.com, wrote to complain that he'd been redirected from an article about ipchains to a porn site. How did that happen? The Internet domain name from which the original ipchains homepage was served had lapsed, and was then squatted upon. I updated our page to point to a correct ipchains homepage2, but what about all the other references to the original? Some might find a certain kind of black comedy here -- as when www.linuxchix.org winds up unwittingly sending readers of an ipchains review to a page entitled "Euro Teen Sluts" -- but really it's just depressing. (Yes, I alerted the LinuxChix to the problem.)
On the same day that I discovered the ipchains switcheroo, somebody else wrote complaining that he couldn't find the report that I wrote last year on Internet groupware for scientific collaboration. Published in connection with the Software Carpentry Project, and widely cited around the Net, the report vanished in the wake of a recent site reorganization. Happily, in this case, the site maintainer was willing to redirect to a version of the report3 that I've now hosted on my own server. As I chatted by email with this fellow -- he's Mark Mitchell, who has written articles for Dr. Dobb's and Linux Magazine (small world!) -- he commented on the sorry state of digital archiving:
One of the nice things about a good old-fashioned library is that the librarians tend not to throw out the books. In another 20 years it may be easier to find math journal papers from 1973 than computer science articles from 2003, if we're not careful.
As if that weren't enough, another email came on the same day from somebody looking for "an article published in BYTE between 1978 and 1988, entitled Brain, Man, and Machine." That era precedes the BYTE CD-ROM, which spans only 1990-1998. Sadly, when I produced that CD-ROM, there was no economical way to recover prior issues from a welter of electronic and pre-electronic formats. So the query prompted me to take another look at bibliographic resources on the web. All paths converged on Nelson Beebe's bibTex archive, reformulated in many places and in many ways including a searchable version4. Here's the distribution of BYTE citations recorded by this labor of love:
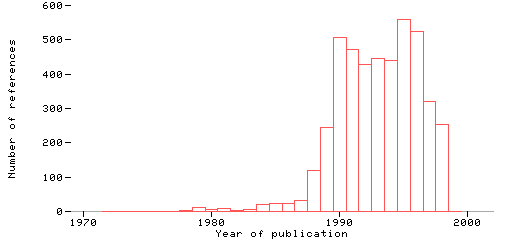
As far as I can tell, Beebe's compendium of citations is more complete than most, if not all, of the BYTE bibliographic resources5 known to the Online Computer Library Center (OCLC). But alas, no "Brain, Man, and Machine" -- if someone remembers it, please let me know and I'll pass it along.
Sherman, set the Wayback Machine to 1996
It was, all in all, a gloomy day. And then a ray of sunshine broke through the clouds. I'd seen references, on Dave Winer's Scripting News site, to new and exciting activity at the Internet Archive. Founded in 1996 by Brewster Kahle, these collections -- gathered by Alexa Internet, the engine that powers Netscape's "What's Related" feature -- were available to researchers, but not easily accessible to the general public. That changed suddenly and dramatically on October 24 with the unveiling of the Wayback Machine6, which brings the archives to life. This remarkable service instantly creates a new and wildly powerful web namespace. In fact, it creates many namespaces -- a whole series of them for each website, each a historical snapshot of some prior state of the site. In one of those snapshots, for the Software Carpentry site, I found a copy of my groupware report.
It's too early to tell what will be the long-term impact of this exciting new development. Can such an effort be sustained? Within hours of its release, the Wayback Machine was brought to its knees by a surge of demand. Still, I wouldn't bet against it. The OCLC reports that the rate at which the number of Internet sites is growing has begun to flatten; meanwhile Moore's law keeps going strong.
I don't think that the genie can, or should, be put back into the bottle. The Wayback Machine, and/or services like it, will certainly become a feature of the new Internet landscape. This immediately raises a series of fascinating issues and questions.
Copyright. The Archive's terms of use forbid copying of its material. But does it violate copyrights by including the material in the first place? The Archive claims not:
Our collections consist of publicly available documents. Furthermore, our Web collection includes only pages that were available at no cost and without passwords or special privileges. And if they wish, the authors of Web pages can remove their pages from the collection.
If the Archive's caching raises questions, should Google's too?Automatic "404 Not Found" resolution. If the Archive proves reliable, we may well soon see servers and/or clients, upon encountering 404s, try to fail gracefully by redirecting to the most-recently-saved archive page. This would be more than a major convenience. It could help bring hypertextual writing finally into the mainstream. Linking is the most profound way in which the web alters (or should alter) how we communicate. The lack of widespread and easy-to-user hypertext writing tools has been an impediment. But the vexing problem of linkrot is the real barrier. We won't collectively invest much effort in weaving the web until we can begin to regard its namespace as less fragile than it has so far proved to be.
Parallel universes. When you wander into the alternate spaces created by the Archive, it can be hard to find your way out. Within a snapshot, links refer to the archival namespace, not the real web namespace. It requires effort to switch back into web namespace. Users will therefore miss the most current version of pages. Publishers depending on ads (which the Archive generally does not display) would, of course, prefer that archival space be used only for otherwise inaccessible material. Conceivably, along with an automatic resolve-backward mechanism, we might also see demand for an automatic resolve-forward mechanism that makes archive patrons aware of original pages when they exist.
Future-proofing. In an earlier column, Web Namespace Design7, I talked about how simple and consistent URL namespaces can help make content portable, and thus more durable. A corollary, which the Archive dramatically illustrates, is that simple, clean, and basic content -- just HTML and images -- best survives the transition into archive space. Of course you can (and should) generate the HTML using any fancy technique that you want. I would, in fact, recommend that you generate XHTML, just because it's easy, and buys even more future-proofing. But be aware that if you rely on new and less standardized techniques, such as dynamic HTML, you are probably making something that will fail embarrassingly when seen from the future.
For me, the Wayback Machine arrived in the nick of time. Literally on the same day I had begun archiving, on my own site, things that I reluctantly concluded the web would not preserve. I guess I'll continue to do so, in some cases, when the canonical locations I'd rather refer to stop working. But there is great relief in knowing that the Internet Archive will -- let's hope -- offset the web's growing amnesia.
The LOCKSS System
To cap the string of coincidences, I also learned -- again on the same day -- of another noteworthy archival project called LOCKSS, for Lots of Copies Keep Stuff Safe. This Stanford and Sun Microsystems project, headquartered online at http://www.lockss.org/, aims to assure libraries of ongoing access to web journals. As the project's FAQ8 points out, libraries are leery of subscribing to web journals that may become unavailable, but can't afford not to as more content is published only online.
The LOCKSS system proposed to solve this problem is very unlike the massively centralized Internet Archive. It is, instead, an open source project that implements a distributed cache. The cache ensures the integrity of local collections on behalf of library patrons, and replicates collections to other libraries that have legitimate access to them. It does not preempt the online journals. The cache is purely a fallback, in case primary access fails or is discontinued.
Described as "an Internet appliance for preserving e-journals," a LOCKSS instance runs on a dedicated Linux PC of modest strength with standard parts and no non-essential services. Every time it boots, the PC fetches the LOCKSS software (and the Java VM that runs it) from the Internet, then fires up a LOCKSS instance which joins others to form a virtual network.
The cache protocol is called LCAP (Library Cache Auditing Protocol). This peer-to-peer multicast protocol is described in a paper9 by the LOCKSS architects, David Rosenthal and Vicky Reich. It's used to implement polls by means of which the network can verify and maintain the integrity of the distributed cache. There's no effort to use PKI-based certificates or signatures to assure integrity. These methods, the designers believe, will not remain viable long enough. Instead, LOCKSS adopts a more PGP-like trust mechanism:
The approach we're experimenting with in LOCKSS is to divide guys into good and bad by observing and remembering their behavior over a period of time. For our purposes, a good guy is one who:
- maintains a good copy of the journal content,
- votes in polls to prove that the copy is good and to help others prove that their copies are good too,
- remembers that others have voted in the majority for a long time,
- and supplies good copies to others when requested to repair damage.
A bad guy is one who, among many potential crimes:
- votes too early or too often,
- votes on the losing side of too many polls,
- fails to verify their vote on request,
- or supplies bad copies to others.
Note that these are all public actions, observed by others.
By design, the process works very slowly. It is not concerned to preserve snapshots of today's weblogs for use next year. Rather, in the spirit of the Long Now Foundation10 which is one of its sponsors, LOCKSS is taking a very long view of its mission.
Nothing lasts forever. But the web needn't be as ephemeral as it has become. Here's hoping that the Internet Archive, LOCKSS, and other archival projects will help us strike the right balance between volatility and permanence.
Links
- http://udell.roninhouse.com/archive/citrixFirstImpression.html
- http://netfilter.filewatcher.org/ipchains
- http://udell.roninhouse.com/archive/GroupwareReport.html
- http://liinwww.ira.uka.de/bibliography/Misc/byte.html
- http://www2.oclc.org/oclc/fs/fstitle/results_issn_search.asp?issn1=0360&issn2=5280&database=%25
- http://web.archive.org/
- http://www.byte.com/documents/byt20010705s0002/0709_udell.html
- http://lockss.stanford.edu/projectdescfaq.htm
- http://lockss.stanford.edu/freenix2000/freenix2000.html
- http://longnow.org/
Jon Udell (http://udell.roninhouse.com/) was BYTE Magazine's executive editor for new media, the architect of the original www.byte.com, and author of BYTE's Web Project column. He is the author of Practical Internet Groupware, from O'Reilly and Associates. Jon now works as an independent Web/Internet consultant. His recent BYTE.com columns are archived at http://www.byte.com/tangled/

This work is licensed under a
Creative Commons License.