Tangled in the Threads
Jon Udell, March 14, 2002Thinking by analogy
In a column last month on general-purpose scripting I identified two major axes: language and environment. Freedom to innovate in the language domain is a wonderful thing, but scripting languages pay for that freedom by recreating complete environments in which to operate.
Lately, while adding a new arrow to my scripting quiver -- Frontier's UserTalk -- I've had a chance to observe first-hand the process of mapping knowledge from one environment to another. For my weblog, I developed a feature I'm calling a channelroll. It's like the blogrolls that decorate so many weblogs but one step more abstract. In addition to the URL of each site that mentions, it offers a link to the site's RSS channel, and another link (currently useful only to users of Radio UserLand) that invokes the one-click-subscribe feature in Radio.
I wrote the script as a Web service. A variation of the ones I wrote about last time, it returns a string of formatted HTML rather than structured data. Why a Web service? It's gratuitous in this context, I must admit, as Sam Ruby noticed when he decided to implement the widget as a simple macro, rather than an XML-RPC/SOAP endpoint. What I envision, for later, is automated social network analysis based on this information, but in that case a structured-data flavor of the widget would make most sense.
In any event, the script's major task is the same: extract data from a table in Frontier's object database, sort it, and emit HTML. Given a Perl hashtable or a Python dictionary, I'd have made quick work of the job. Doing just that was, in fact, an option. I could imagine creating another Web service that would export the data from Radio to Perl or Python, where it could be munged in a friendly and familiar environment, and then returned as a string to Radio. But there are just too many moving parts in that scenario. This widget works in the context of a scripting engine that's local to the desktop; once delivered there, it shouldn't need to rely on anything external unless absolutely necessary.
Here's the script:
on subs()
{
local (t);
new (tableType, @t);
for adr in (@aggregatorData.services)
{
local(title = adr^.compilation.channeltitle);
local(channelUrl = adr^.compilation.channellink);
local(rssUrl = nameOf(adr^));
local (l);
new (listType, @l);
l[0] = channelUrl;
l[0] = rssUrl;
t[title] = l;
};
target.set(@t);
table.sortBy("Name");
target.clear();
local(s = "<p class='realsmall'>currently subscribed to:</p>");
for adr in (@t)
{
local(title = string.replace(nameOf(adr^),"'","'"));
local(l = adr^);
local(channelUrl = l[1]);
local(rssUrl = l[2]);
s = s + "<p class='realsmall'> \
<a href='http://127.0.0.1:5335/system/pages/subscriptions?url=" + rssUrl + "'> \
<img border='0' src='http://radio.weblogs.com/0100887/images/my/tinyCoffeCup.jpg' \
alt='Radio UserLand users: click to subscribe. Other folks: use the RSS link to \
acquire this channel.'></a> <a href='" + rssUrl + "'> <img border='0' \
src='http://radio.weblogs.com/0100887/images/my/tinyXML.jpg' alt='RSS link'></a> \
<a href='" + channelUrl + "'>" + title + "</a></p>";
};
s = s + "<p class='realsmall'>Here's \
<a href='http://radio.weblogs.com/0100887/2002/02/24.html#a88'>how this works</a>.</p>";
return (s);
}
Very simple, yet it took much longer than I'd have liked to figure it out. I have the impression that many people believe most of the friction, when moving from one programming language to another, arises from differences in the syntax of the languages. I'm not so sure. True, it took me a little while to grok UserTalk's @ and ^ operators, to figure out that assigning to l[0] builds the list, and to realize that UserTalk lists and tables must be declared as such. But that's not where I lost the most time. What really slowed me down was not knowing how higher-level idioms -- visualizing the contents of a table, sorting the table -- mapped into UserTalk.
After the first for loop, the variable t should contain a hash-of-lists (in Perlspeak), with each key being a channel's title, and each value a list of two URLs. Years of Perl experience have taught me to reach for the trusty Data::Dumper module in order to inspect data structures, and verify they are what I think they should be. Here's what I'd have done in Perl:
use Data::Dumper; print Dumper($t);
In Radio, those years of Perl experience led me far astray. I went looking for the wrong thing -- a function that would dump out a data structure -- and so I found the wrong thing, in the form of the table.TableToXML verb. It was wrong for a number of reasons. The resulting dump is not particularly readable. Worse, when examined in Radio's QuickScript window, the text is truncated. What I really wanted was to inspect the table in Radio's outline editor, the same one used to inspect and edit all the other code and data sitting in the object database.
Oh. Of course. The answer wasn't to dump out some inferior text representation of my data structure, but rather to assign it to the object database and make use of its superior data viewer. Like so:
scratchpad.foo = t;
Now, the table can be viewed, and edited, like so:
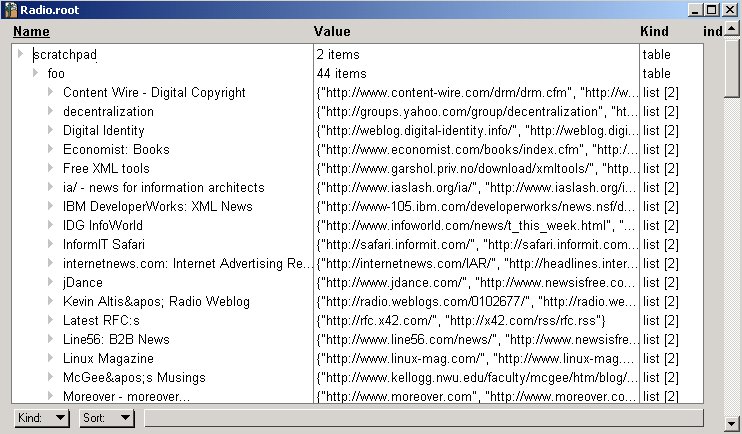
A table variable assigned to a slot in the database (click to enlarge)
See what I mean? My Perl experience didn't condition me to expect this, so I didn't look for it. My Python experience did condition me to expect this, since almost all my Python coding is done in the context of Zope, but even there, I wouldn't expect to be able to assign an arbitrary dictionary to the ZODB and then inspect it using Zope's management UI.
The next example is more of the same kind of thing. It was clear that table.sortBy was what I needed to sort my table by channel titles. Doing that, however, produced an error. The documentation provided a clue: "If the target window does not contain a table, an error message will be displayed." Despite my recent discovery that scripting, in Radio, is closely coupled to the GUI environment of the outliner, it still took me a while to realize that target meant the target window (even if invisible) containing the table.
Fluid concepts and creative analogies

|
|
Basic Books
ISBN: 0465024750 Price: $24 USD |
The best framework I have for thinking about these kinds of mapping issues is Douglas Hofstadter's wonderful Fluid Concepts and Creative Analogies: Computer Models of the Fundamental Mechanisms of Thought (Amazon link). I reviewed the book for BYTE, when it first came out, and I've been thinking about it ever since.
The question I was really asking was:
What is the Data::Dumper of Frontier?
This is one of a general class of puzzles that Hofstadter, following Guglielmo Belpatto (a 19th-century Italian scholar whose delightfully anagrammatic surname seems to appear only in Hofstadter's book), refers to as "Ob-Platte puzzles":
Thus a shivering Siberian contemplating emigration to the Great Plains of the United States might worriedly inquire, "But what is the Ob of Nebraska?" Knowing, of course, that the Ob is the mighty river traversing Siberia, any red-blooded Nebraskan would proudly reply, "The Platte, of course!"
Much of the book explores the following interrelated notions:
That human intelligence is deeply connected to this process of analogy-making.
That an analogy seeks to bind together many features of the domains it connects.
That the number of such features explained, and quality of the explanations, governs the power of the analogy.
That high-quality analogies are hard to find, but easy to recognize once found, and deeply satisfying.
I wish someone would write a book that would solve Ob-Platte puzzles like:
{kind=link}
What is the Make::Maker of Ruby?
What is the Zope of Perl?
What is the DOM of Frontier?
It's true there are books that specialize in cross-domain mapping. O'Reilly's SQL in a Nutshell, for example, correlates SQL usage for Oracle, SQL Server, MySQL, and PostgreSQL. But these mappings don't have to work too hard. Consider, however, some possible answers to the question, "What is the Zope of Perl?":
Zope, because Zope can be scripted using Perl.
HTML::Mason, because it's a Perl-based content-management system that builds pages by means of reusable components.
SPOPS, because it's an object-database API for Perl.
These analogies address some of Zope's many aspects, but none seems particularly satisfying. Analogies are all we have to work with, when trying to connect very different domains, but high-quality analogies are hard to come by. Data::Dumper and Radio's outliner are very different creatures. Once you see the connection, the analogy is deep, satisfying, and useful. Would it even be possible to develop an interesting collection of these analogies for, let's say, Perl, Python, JavaScript, UserTalk, Ruby, and PHP? I'm not sure. If you're involved in one culture deeply enough to see the essence of a problem from one perspective, you're almost by definition not able to see it from the perspective of another. Maybe a team of collaborators could write the book I'm imagining. I'd sure love to read it!
The New Penguin Dictionary of Computing

|
|
Penguin Books
ISBN: 0140514376 Price: $28 USD |
I'll conclude this bookish column with a plug for a new reference book by my old friend Dick Pountain, author of many excellent articles in BYTE over the years.
Three years in the making, Dick's opus is called The New Penguin Dictionary of Computing: An A-Z of Computing Jargon and Concepts. It's a great way to cut through the acronym fog that clouds our industry. How many meanings can you think of for ATM? Dick comes up with one more than I would have:
Abbreviation of Asynchronous Transfer Mode
Abbreviation of Adobe Type Manager
Abbreviation of Automated Teller Machine
Online shorthand for At the Moment
When Dick defines ARM (Acorn RISC Machine), Gouraud shading, PVM (Parallel Virtual Machine), and SIMD (single-instruction, multiple-data), you're hearing it from the horse's mouth: he's the one who very likely introduced BYTE readers to these subjects.
Lots of fun to browse through, and useful to keep on the shelf.
Jon Udell (http://udell.roninhouse.com/) was BYTE Magazine's executive editor for new media, the architect of the original www.byte.com, and author of BYTE's Web Project column. He is the author of Practical Internet Groupware, from O'Reilly and Associates. Jon now works as an independent Web/Internet consultant. His recent BYTE.com columns are archived at http://www.byte.com/tangled/.

This work is licensed under a
Creative Commons License.