Tangled in the Threads
Jon Udell, April 24, 2002The Google API is a two-way street
Google's new SOAP API seemed to follow a boom-and-bust trajectory. Everyone was excited about it until it arrived. Then doubts arose. "Bah!" scoffed Edd Dumbill in an O'Reilly Network column, "what a waste of space for something that can be done in one line of shell script." Edd's point -- that an HTML-screenscraping alternative to the Google SOAP API is easy to hack together -- is quite correct. But the conclusion -- that Google's SOAP API is silly -- is, I think, very wrong.
From the start, the web was a network of programmable services. I first pointed this out in a 1999 article, Measuring Web Mindshare, which combined two proto-services -- Yahoo's directory, and AltaVista's link-counting -- to create a novel service that ranked sites in a Yahoo category by the number of AltaVista links pointing to them. The "web mindshare" that's computed by this synthesis is, of course, exactly what Google measures.
For web services, all the real juice is in the network effect. As amazing as Google is, it is only a single service. To repeat my 1999 experiment today, I'd still have to screen-scrape Yahoo, or the Open Directory, in order to emulate a directory-enumeration API. This, too, can be done with /bin/sh, or Perl. But that cuts across the grain. It requires skills that many people don't have, and effort that most people won't want to invest. Pervasive SOAP APIs will be a difference in degree that adds up to a difference in kind. The activation threshold for making new connections will fall below some critical point. The telephone network isn't interesting when there's only one phone. Google, equipped with a standard API, is a telephone. Soon there will be many more, equipped with the same standard API, and then the lines will really start to buzz.
That said, Google's API has provoked some nifty experiments. In The Mind of Google, Dave Winer reports on an outline-based explorer that transitively lists sites found using Google's "similar pages" feature. Starting with a site, for example http://udell.roninhouse.com/, you produce a list of 10 related sites by calling the Google API with the query related:http://udell.roninhouse.com/. Repeat for any of those 10 sites.
Google outline browsing in another dimension
The results of Dave's mode of exploration are the same as if you follow Google's own "similar pages" links but, because the outliner is a context-preserving medium, the effect is different. Inspired by Dave's idea, a number of these Google explorers popped up. The one I latched onto was Kenytt Avery's YAGOB (Yet Another Google Outline Browser). Kenytt stood on the shoulders of giants when building this handy tool. One is wxWindows, a cross-platform GUI toolkit created by a team of talented hackers. Another is Robin Dunn's wxPython, which makes wxWindows scriptable in Python. Still another is Mark Pilgrim's pygoogle, a Python wrapper for the Google API. Thanks to all this excellent infrastructure, Kenytt Avery was able to write an elegant GUI outline browser in just a few lines of Python.
This was a a great excuse to update myself on wxPython, which keeps on improving. So I did that, installed pygoogle, and embarked on an outline-oriented exploration of Google. It was fun, but something seemed wrong. If you start with http://udell.roninhouse.com, here are the first ten related sites:

The wxPython app used here is based on Kenytt Avery's YABOG.py, but adds a companion window (derived from wxTreeCompanionWindow) that's slaved to the left-pane tree control, in order to be able to display both URLs and doctitles.
Exploring this way was fun, but the connections that were made didn't excite me as much as I'd expected. Many of te first 10 sites, though groupware-related, didn't seem very closely connected to my work or my interests.
Then it struck me. Searching by related URL is not how I primarily use Google. In real life, I query for words and phrases. So I adjusted the script to do a normal Google search, queried for "Jon Udell groupware," and got this result:

That looked promising. Now, how could I feed the snake's tail back into its mouth? What words or phrases could be used to continue the search in this way, rather than proceeding with related URLs as before? Of course! It was staring me right in the face. The document titles produced at each level could be the search terms for the next level. The modified explorer (source code here) produces results like so:
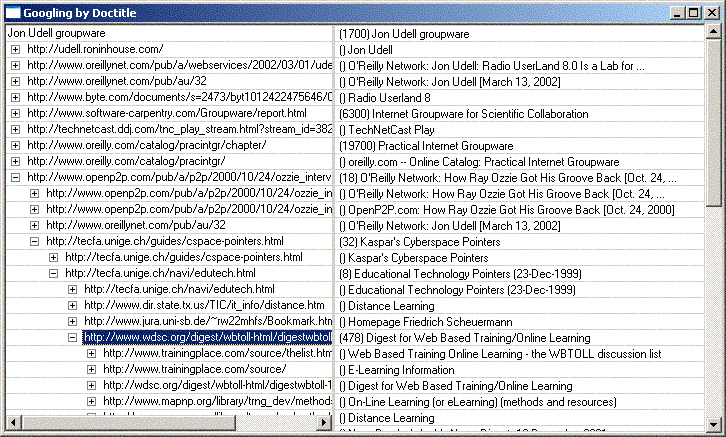
This felt more productive. My O'Reilly Network interview with Ray Ozzie led to Kaspar's Cyberspace Pointers, which led to Educational Technology Pointers. Paths through this doctitle space seem to diverge more than paths through related-URL space, in ways that are often (but by no means always) interesting.
The limiting factor, of course, is the quality of the doctitles. These titles, written in the <TITLE>...</TITLE> tag of an HTML page, are one of the web's most underutilized resources. In an earlier column I showed how HTML doctitles can be managed as metadata and used to organize search results. The same topic is explored much more deeply in Chapter 8 of my book. There, I show that the primary API of every website is a pair of namespaces. One is made of URLs. When these are controlled by content management systems, they can form patterns that may be noticed and exploited by other systems. This gets really powerful when search systems use the metadata patterns to categorize found items by date, topic, or along other dimensions. The other namespace is made of document titles. These too can be controlled by content management systems. Sets of doctitles can made to act like a metadata store that complements the information load carried by the URL namespace.
The crucial point about URL and doctitle namespaces is that Google, and indeed every search engine, will give them back to you in response to a query. And that's what I mean when I say that the Google API is a two way street. It's great that Google now exports an API, but it also behooves you to think about the API that your site exports to Google, and now (thanks to Google's API) through Google to other kinds of consumers.
Enhancing Radio Userland doctitles
Imagine my surprise, then, when I pointed my doctitle-oriented Google browser at one of my weblog pages on Radio Userland and discovered that every single one of those pages was entitled "Jon's Radio." Given my longstanding interest in forming and then exploiting rich doctitles, you'd think I would have noticed this sooner. The mindless repetition of the homepage title on every archive page wastes a precious asset, exactly as I counsel other people not to do. It made searches of my own weblog (using the Texis-based service at master.com) much less interesting than they should be, and it also made my site useless for my modified Google browser.
I had to fix this. Since Radio Userland is a programmable content management system, it was obviously possible to do so. And after a few twists and turns, I succeeded. My first idea was to replace the <%title%> macro in the Radio templates with something smarter, perhaps wired to the callback mechanism that fires when an item is published. But there didn't seem to be a way to pass such a macro the necessary context -- that is, the address of the published item.
A bit more spelunking turned up an interesting fact. Radio's archive pages are really just placeholders, containing metadata but no real content. Here's a sample archive page stored on my system as c:/radio/www/2002/04/23.txt:
#flHomePage true #flArchivePage true #archiveDate "2002/04/23" <%radio.macros.viewWeblog ()%>
What would happen, I wondered, if I added some new metadata like so:
#title "The practical benefits of literary forms" #flHomePage true #flArchivePage true #archiveDate "2002/04/23" <%radio.macros.viewWeblog ()%>
Voila! Making this edit, by hand, caused the page to be republished with the desired title. So it was only necessary to automate this process.
Matters were a bit more complicated because I sometimes write more than one item a day. In such cases, what should be the title for the archive page on which all the items appear? All of the titles? Just one of them? In the end I decided to use the newest item on the page. This is an imperfect solution, as all metadata mapping is, but it's also far better than the default, which would be to uselessly repeat "Jon's Radio."
The procedure that took shape, then, was to scan the table of weblog postings, compare titles in the database to titles that did or didn't exist as metadata in the archive page files, and add titles to the archive page files (or modify their titles) as needed. Initially, I was still thinking in terms of the publishItem callback, which receives the database address of an item when it's posted. This worked, but in a sorcerer's apprentice kind of way. Each time the script rewrote an archive page to update its title, it caused the page to be published, which in turn triggered a new callback to the script.
The solution I hit on was to write an agent script (i.e., a script stored in Radio's system.agents table) and run it on a scheduled basis. Here is that script. Commentary starts near the bottom at 1, skips to the top at 2, then runs through to 10 at the bottom again.
A Radio Userland script to retitle weblog archive pages
on retitleArchivePage (adrPost)
{
if defined ( adrPost^.title ) == 0 // 2
{ return };
scratchpad.thisPost = adrPost^; // 3
new (tableType, @match); // 4
regex.easyMatch ( "([0-9]+)/([0-9]+)/([0-9]+)" , adrPost^.when, @match);
scratchpad.match = match;
month = match.groupStrings[1];
day = match.groupStrings[2];
year = match.groupStrings[3];
d = month + "/" + day + "/" + year;
scratchpad.d = d; // this is the date form in the when field of a post
// 5
scratchpad.archiveDate = year + "\\" + string.padWithZeros(month,2) +
"\\" + string.padWithZeros(day,2); // canonical form
scratchpad.archivePath = "c:\\radio\\www\\" + scratchpad.archiveDate + ".txt";
scratchpad.archiveFile = string ( file.readWholeFile(scratchpad.archivePath) );
new (listType, @l);
for adr in (@weblogdata.posts) // 6
{
if ( regex.easyMatch ( d, adr^.when ) )
{ l[0] = nameOf (adr^) } // gather posts on same date
};
// 7
scratchpad.mostRecent = l[sizeOf(l)]; // use most recent title for archive data
if defined ( weblogdata.posts.[scratchpad.mostRecent].title ) == 0
{ return };
scratchpad.title = "\"" + weblogdata.posts.[scratchpad.mostRecent].title + "\"";
// 8
if ( regex.easyMatch ( "#title " + regex.quoteRE(scratchpad.title) ,
scratchpad.archiveFile, @match ) == 0 )
{ // missing/wrong
if ( string.patternMatch ( "#title", scratchpad.archiveFile ) == 0 )
{ // missing
scratchpad.archiveFile = "#title " + scratchpad.title + "\r\n" +
scratchpad.archiveFile;
scratchpad.[adrPost^.title] = "action: added"
}
else { // wrong
regex.subst ("#title .+", "#title " + scratchpad.title + "\r\n" +
scratchpad.archiveFile, @scratchpad.archiveFile);;
scratchpad.[adrPost^.title] = "action: changed"};
file.writeWholeFile( scratchpad.archivePath, scratchpad.archiveFile );
scratchpad.[adrPost^.title] = scratchpad.[adrPost^.title] + ": file rewritten"
};
for adr in ( @weblogdata.posts) // 1
{ retitleArchivePage ( adr ) };
msg ("archive titles updated at " + clock.now()); // 9
clock.sleepFor (60*60*4) // sleep 4 hours // 10
Script commentary
1. Call retitleArchivePage for each posted item.
2. Not every item has a title. If there is none, bail out.
3. Put the table of data about the posted item onto the scratchpad. It could also go into a variable, but the viewable and editable scratchpad is great for debugging.
4. Use Radio's regex extension to capture the month, day, and year of the posted item's date. These elements will be needed twice -- first like "4/23/2002" to match other items on the same date, and second like "2002/04/23.txt" to form the filename of an archive page.
5. Use the second form of the date to form the path to the archive page. Then read its contents into a string stored on the scratchpad.
6. Make a lists of posts on the same date as the current post (using the first form of the date to match them).
7. The last item in the list is the most recent posting for the date. If it doesn't have a title, bail. If it does have a title, quote it and save it on the scratchpad.
8. Does the archive page text contain the title? If not, the title is either missing or, because superseded by a newer item, wrong. If missing, add it to the archive page. If wrong, replace it. In either case, rewrite the file and make a note on the scratchpad to that effect.
9. After processing all postings in this way, send a message from the agent announcing completion. These messages appear in a special menu inside Radio's About box -- the same place that's normally used for status messages.
10. Sleep until awakened to repeat the job.
Ask not what Google can do for you
Google hasn't caught up with these changes yet, but I've already seen some nice results. Today when I followed a referral to my weblog back to its source, I saw that my new and improved title popped up when I hovered over the link. Once Google does catch up, I expect my title-oriented explorer will lead to some interesting new connections. So don't ask only what Google can do for you. Ask also what you can do for Google, and for the web, by making the most of the metadata you publish.
Jon Udell (http://udell.roninhouse.com/) was BYTE Magazine's executive editor for new media, the architect of the original www.byte.com, and author of BYTE's Web Project column. He is the author of Practical Internet Groupware, from O'Reilly and Associates. Jon now works as an independent Web/Internet consultant. His recent BYTE.com columns are archived at http://www.byte.com/tangled/.
