 |
by Jon Udell
"It's a nice idea," said editor-in-chief Mark Schlack of ByteCal, my servlet-based calendar program, "but I can't use it." Why not? Like all Web-based software, ByteCal presumes that its display -- a browser -- connects through the Internet to an HTTP server.
How hard could it be, I wondered, to run the servlet locally on a disconnected client? Not very hard at all, I found. That discovery prompted me to write a contact manager based on a tiny Web server written in Perl. These two very different applications share a set of interesting properties:
The principle at work here, best articulated in the writings of Bob Orfali, Dan Harkey, and Jeri Edwards, is that the client/server architecture of today's Web today will inevitably evolve into a peer-to-peer architecture. Many of the nodes of the intergalactic network they envision will be able to function as both client and server. I've always bought into this vision, but until recently I couldn't see a practical way to apply it. The answer, I think, is that servers needn't be the complex beasts we usually make them out to be. They can in fact be much simpler than the behemoth client applications we routinely inflict on ourselves. In that simplicity lies amazing power.
Could local-Web-server technology help solve the application-development challenges associated with a typical contact manager? On a hunch that it might I dusted off tinyhttpd.pl, a classic Perl gem that implements a simple Web server in about 100 lines of code. I threw away the file-serving and CGI-execution parts, leaving just a simple socket server that could accept calls on port 80 and extract data sent using the GET or POST methods.
In normal Perl CGI, a URL like /sfa_01?who=jon&when=today causes the Web server to launch the Perl interpreter against the script named sfa_01, which script in turn receives the URL-encoded data who=jon by one of several means. High-performance variants such as ISAPI Perl and mod_perl keep the Perl interpreter in memory.
The same high performance arises when Perl itself implements the Web server. This model doesn't make sense for heavily-trafficked public sites. But it makes a great deal of sense for a local Web server (or a lightly-loaded intranet server). In my system, the script name in a CGI-style URL becomes a function name with arguments. For example, the server converts /sfa_01?who=jon&when=today into the function call &do_sfa_01('who=jon&when=today').
What are these Perl functions in a position to do? Here are the key things:
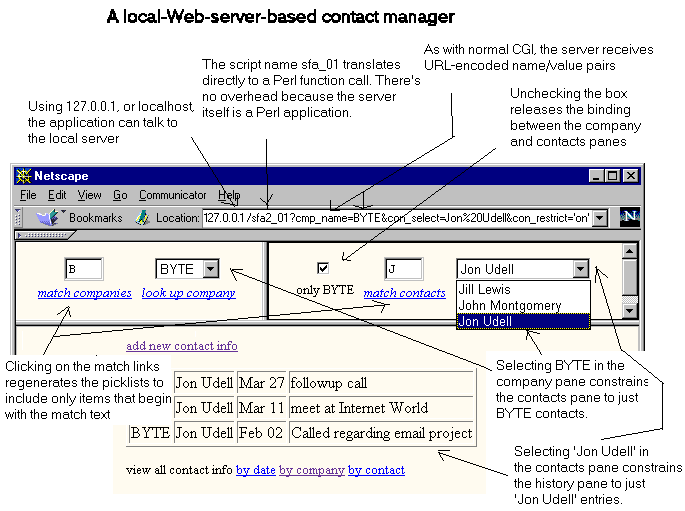
These Perl capabilities, combined with some homegrown conventions for using HTML and JavaScript, yielded the first version of SFA (which stands for "sales force automation", shown here:
|
You can find this version at http://udell.roninhouse.com/download/sfa.zip. Now I don't pretend you'll want to dump Ecco or Act in order to use this prototype. It's just a sketch of a contact manager, but it does exhibit some interesting features including:
We expect these kinds of search, navigation, and data-entry idioms from applications written in FoxPro or Access. We don't expect them from Web-style applications that play to pure Web clients. Should we? Does it make any sense to position the combination of an HTML/JavaScript browser, ODBC/JET, and a local-Web-server-cum-script-engine as an application platform?
A number of factors weigh in favor of this approach. Perl is vastly more capable than the FoxPro or Access or Notes dialects typically used to script this kind of application. The resulting application is small and fast. It relies on an existing and familiar client. Like Notes (but unlike FoxPro or Access) it exhibits complete local/remote transparency.
There are also drawbacks. Browsers don't support data-entry idioms such as accelerator keys and custom field-tabbing. JavaScript is flaky. The methodology, an intricate tapestry of signals, substitutions, and redirections involving Perl, HTML, and JavaScript, is complex.
I've implemented dhttp in Perl, but the system is small enough and simple enough at this point so that it could easily be redone in Python or another versatile and socket-aware scripting language. What matters is not the language itself, but the strategic position in which a dhttp system situates that language. From the perspective of a single dhttp node implemented on a standard Win95 PC, the script language can transmute local file, SQL, and OLE resources into applications that play to local or remote Web clients. In a dhttp network the script language is even more radically empowered. Replication of SQL data among the nodes of the network turns out to be a shockingly easy problem to solve. Likewise replication of code. When I accomplished both of these things in the same day, I had to stop and take more than a few deep breaths. Could a system so simple really be this powerful? Perhaps it can. I'll explain how it works; you can try it yourself and see what you think.
To create dhttp (http://udell.roninhouse.com/download/dhttp.zip), I refactored the original sfa system in order to separate the server from the applications that it hosts. Two demo applications are included. Sfa is a more advanced version of the contact manager included with sfa.zip. It features an enriched data viewer, uses more sophisticated polymorphic HTML widgets, supports editing as well as viewing, and remembers change history in order to enable data replication. Bmark is a tool that consolidates BYTEmark results into a database, and exports HTML views of that database.
I wrote bmark for three reasons. First, we needed it. Tracking BYTEmark results was a somewhat haphazard affair; with bmark, BYTE staffers anywhere on our intranet could upload a BYTEmark output file or review the results database. Second, I needed to create a model that would enable an instance of the server to host multiple applications, and that meant there had to be at least two apps. Third, I wanted to test whether that model would make sense to someone else. So once I got bmark working as a dhttp-based plug-in, I turned it over to my associate Dave Rowell for refinement.
Here's a picture of the current dhttp architecture:
 |
The engine divides into three modules -- the server itself, a set of public utilities, and a set of private utilities. A public utility, in this context, is one that a Web client can call by means of an URL. A private utility, on the other hand, is visible only to local dhttp components -- either the server itself, or any of its plug-in apps. An example of a public server utility is do_engine_serve_file. It responds to the URL /engine_serve_file?app=bmark&file=upload.htm by dishing out the file upload.htm from the dhttp/lib/apps/bmark subdirectory. The prefix "engine_" tells the server to form a reference to the function Engine::PubUtils::do_engine_serve_file and then call that function.
An example of a private engine function is upload_file. It handles the HTTP file upload protocol -- that is, it can parse data posted from a Web form that uses the multipart/formdata encoding, and return a list of parts. I wrote upload_file for the bmark application, but placed it in the package Engine::PrivUtils so that other apps could use it too.
An instance of dhttp hosts one or more plug-in apps, each implemented as a Perl module with its own namespace separate from other apps and from the server. Like the server, each app comprises public (that is, URL-accessible) and private functions. But in the case of an app, both kinds of functions are packaged into a single module. How does the engine tell them apart? The prefix "do_" signals that a function is public.
How do you write the classic "Hello, world" application in dhttp? Create the file dhttp/lib/apps/hello.pm with the following:
package apps::hello;use Engine::PubUtils;use Engine::PrivUtils;sub do_hello_world { print &httpStandardHeader; print "Hello, world"; }In dhttp/dhttp, the main driver, add the line use Apps::hello;. Now the server will respond to the URL /hello_world by calling the function Apps::hello::do_hello_world. Alternately you could create the dhttp/lib/apps/hello subdirectory, and place a hello.html file in it. In this case, dhttp will serve the file in response to the URL /engine_serve_file?app=hello&file=hello.html.
So where's the beef? A conventional server would simply support the URL /hello.html. Why the extra gymnastics to serve a file with dhttp? The answer is that while it's possible to make dhttp serve static files in the same way that normal Web servers do, I haven't bothered to do that (yet) because serving static files is the least interesting thing that dhttp does. Dynamic pages are dhttp's forte. The apps I've done so far generate two flavors of dynamic pages -- HTML/JavaScript templates, and database extracts. With these capabilities in hand, you're at the starting gate with respect to interesting and useful Web development.
One of the fascinating things about dhttp is that it catapults you into that starting gate. Out of the box, conventional Web servers leave you far short of the gate. Sure, they tell you how to map Perl to the cgi-bin directory, but that's just the first step. What about low-latency script invocation? It's up to you to acquire and integrate the necessary stuff -- either ISAPI Perl on Win32, or mod_perl on Unix. What about low-latency database connections? Again it's up to you to piece together a solution. On Win32, this might involve ODBC connection pooling in conjunction with ASP/PerlScript, or alternatively ActiveState's new PerlEx. On Unix, you'll need to figure out Apache::DBI. Only some of the Web developers who deploy Perl-based CGI are in a position to exploit low-latency script invocation. Of that subset, still fewer are able to exploit low-latency database connections. With dhttp you begin with a Perl environment that already solves these two key problems. So while dhttp is indeed small and simple and fast, I don't consider it minimal. It includes the essential ingredients that I always need to add to conventional Unix or NT Web servers in order to prepare them to do useful work.
Every developer who uses Perl on a Web server should be using it to maximum advantage. For high-intensity applications, dhttp doesn't pretend to be a solution. In these cases, you should simply figure out how to put together a persistent and database-aware implementation of Perl. The effort will be repaid many times over.
Where dhttp shines is with low-intensity applications. Scads of these ought to exist, and many more would if the activation threshold for creating them were lower. Bmark is an excellent example. It will be used at most a few times a week. Scalability isn't the issue here; availability is. This application simply needs to exist. It's a natural fit for Web-style development, and if you've already got Perl optimally configured, it's an easy problem to solve. The trick is getting Perl optimally configured.
The more I work with dhttp, the more I'm convinced that it represents the right way to integrate Web/Internet technologies with the mainstream Windows desktop. Something like a dhttp service, I'm arguing, ought to be running everywhere. It defines a new platform. For developers, Windows created a new foundation that brought large memory, a GUI, and device independence. dhttp adds a lightweight and radically programmable HTTP service. To see what this might mean, let's consider how to deploy bmark. Until recently, I'd have built it on a conventional intranet Web server in our Peterborough office. But actually the person most responsible for BYTEmark results was Al Gallant, our lab director, who worked in BYTE's Lexington, MA, office. Al would at times want to make wholesale changes to the database outside the scope of the bmark application. Traditionally that would require file transfer, or else file-oriented access across the private WAN -- an option that happened to exist in this case, but isn't always convenient or even available. With dhttp an unexpected new option surfaces. Why not let Al maintain the database -- which is just a .MDB file that he can manage using MS Access -- right on his own Win98 PC?
The ability of Win32 Perl to control other applications by means of OLE automation suggests even more interesting possibilities. Our features editor, John Montgomery, wrote an Excel spreadsheet that emulates McGraw-Hill's expense reports. He had been looking for a way to deploy an "Excel server" that exports an HTML interface across the intranet, logs expense info to a database, populates Excel spreadsheets with information drawn from that database, and then prints those spreadsheets at our Peterborough, NH, office. dhttp is one way to solve this problem, and a rather interesting way given that these spreadsheets could spool into a subdirectory on Linda Higgins' Win95 PC. Since Linda already maintains that subdirectory, and interacts with the expense reports stored there, a dhttp-based agent could fit in very neatly.
Given a network of dhttp nodes, a scripting language such as Perl can achieve a shocking degree of leverage. When I showed the first version of sfa to John Montgomery he asked "What about a drilldown to a biography of each contact?" In about 5 minutes, while John watched, I added that feature. The first four minutes were spent writing the public do_engine_serve_file function, which until then I hadn't needed. It took another minute to wire a call to that function into the sfa data viewer. As you'll see if you download dhttp.zip, the code that does these things is small and simple. In the right environment, it can be.
A week later I added the public function do_engine_sql, which accepts an URL-encoded SQL query and returns a result set formatted as an HTML table. Amazingly, with just 20 lines of Perl, this function transforms a Windows PC into a low-intensity database server. At a single stroke this unlocks the tremendous power of the ODBC interface and the Jet engine -- components that exist on a vast number of desktop machines -- and exports SQL access to local or remote Web clients.
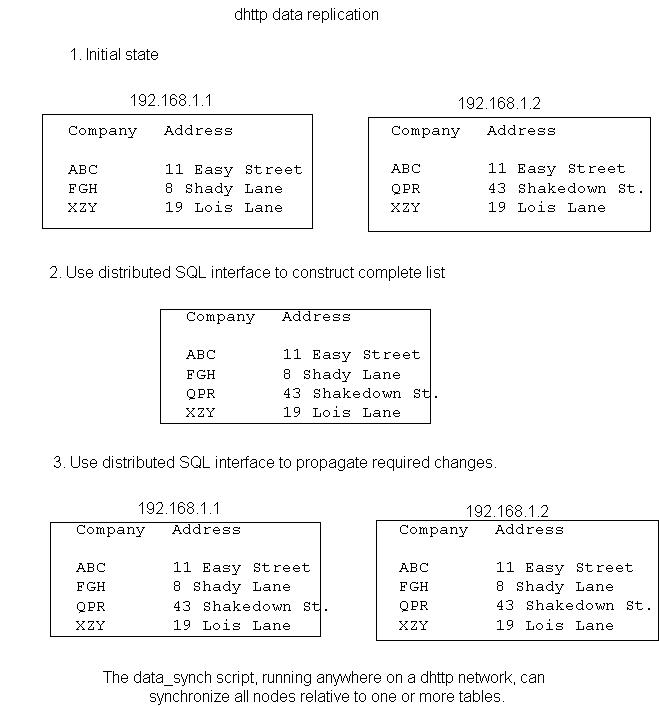
The script data_synch, included with the dhttp kit, combines this remote SQL command-line capability with Web client (URL-fetching) technology. The result is a data replicator that will synchronize any number of tables, across any number of dhttp nodes. The supplied version works on the tables that belong to the sfa application, as illustrated in here:
 |
In a similar vein code_synch (also included) exploits the public engine function do_engine_update_sub. This function receives an URL-encoded Perl function over the HTTP connection, evaluates that function in the namespace of a dhttp plug-in app, and rewrites that app's source code accordingly. Using this function, again with scripted Web client technology, you can project a new version of any of an application's functions into any dhttp node. The modification occurs instantly, without requiring a server restart. When the server does restart, it uses the modified source.
At this point you should be asking a series of questions. How can dhttp's startup/shutdown procedures integrate cleanly with Windows? How are data replication conflicts handled? And most importantly, what about security? I've thought of some solutions, but haven't implemented them yet. I'm releasing dhttp as an open-source project in order to find out if the concept appeals widely enought to merit further work.