In February the W3C approved recommendations to enable annotation on the web. There's a long lineage of annotation tools that enable readers of the web to write comments that overlay content and attach to selections within it. Users of such tools will be happy to know that annotations can now be represented, stored, and exchanged by interoperable clients and servers. But the broader significance of this new standard is that, by defining how applications refer to selections within content, it increases the granularity of the web's address space in ways that benefit many existing applications and will enable new ones.
In text, annotations attach to selected paragraphs, sentences, phrases, or numbers in cells of tables; in images they attach to selected regions; in audio and video to selected clips. The W3C calls these selections segments of interest and defines how to find them within content. We find conventional web resources by way of Uniform Resource Locators (URLs). Such resources contain many possible segments. The act of annotation forms an address that locates a selectable segment within a resource, and reifies it as a new kind of web resource.
"The World Wide Web has succeeded," wrote Roy Fielding in his famous dissertion, "in large part because its software architecture has been designed to meet the needs of an Internet-scale distributed hypermedia system." In the early 2000s, as InfoWorld tracked the then-hot topic of web services, the web's native architectural style, which Fielding called Representational State Transfer (REST), was just coming into focus. Nowadays we more fully appreciate the power of a web of hyperlinked resources accessible at well-known global addresses and manipulated by a few basic commands like GET, POST, and DELETE. Annotation extends that power to a web made not only of linked resources, but also of linked segments within them. If the web is a loom on which applications are woven, then annotation increases the thread count of the fabric. Annotation-powered applications exploit the denser weave by defining segments and attaching data or behavior to them.
That's fairly abstract, so let's make it concrete by exploring a key use case: enterprise content management (ECM). And let's focus on one increasingly typical example. govCMS, hosted on Acquia's cloud, is a platform that "combines Drupal Core and selected modules to enable the quick creation of Australian government websites." It's growing rapidly, with 170 sites live and 25 more in development across 65 government agencies. The benefits of common infrastructure based on cloud-hosted open-source software will be obvious to InfoWorld readers. Within the govCMS community, capabilities and assets built for one website can be shared by all. The platform provides a thematic focus for curation of modules drawn from the broader Drupal community. Content creators learn a common toolset across the federation of sites, and users enjoy a consistent experience across the federation. It's a great story about silo-busting transformation.
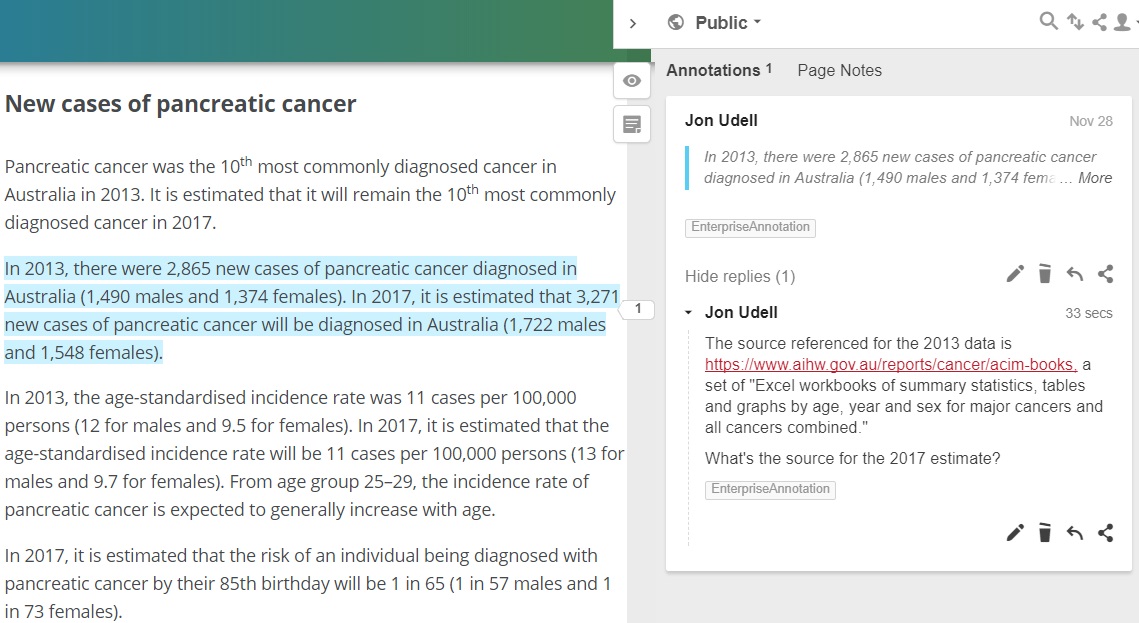
Now let's advance that story. Here's a fact published at https://pancreatic-cancer.canceraustralia.gov.au/statistics:
an estimated 3,271 new cases of pancreatic cancers were diagnosed in Australia in 2017.
Using annotation, I can create an address for that statement and a link that points to it. If you click here you'll invoke a proxy that opens the page, injects the Hypothesis annotation client, highlights the statement, scrolls the browser to it, and opens an editor in which readers can comment on and discuss the highlighted statement.
But the statement annotated in that document is not the authoritative source for the fact. A banner at the top of the page says:
The following material has been sourced from the Australian Institute of Health and Welfare
That link points to the Institute's home page. If you search the site, you can find the page that is the upstream source for the fact. This link points to an annotation that defines the location of the statement within that page:
The annotation I attached to the selection captures it and adds the tag I've been using to gather background for this story. I then replied with a note about the still-further-upstream source for 2013 data, and a question about the estimate for 2017. That kind of question could be raised before publication by writers and editors working in a private annotation layer, or post-pub in a public layer as I've done here. Either way, the question (and ensuing discussion) can be linked to a selected statement in a document.
An annotation has a W3C-standard JSON representation that any standards-based client can retrieve, anchor to a source page in an overlay, or display in another context. In ECM terms, it defines a new kind of reuseable asset, one that's more granular than a whole document but, unlike separately-managed content blocks, lives inside a whole document.
Behind this link you'll find the JSON that represents the annotation shown in the screenshot. It's pretty straightforward:
{
"body": [{
"type": "TextualBody",
"value": "",
"format": "text/markdown"
}, {
"type": "TextualBody",
"purpose": "tagging",
"value": "EnterpriseAnnotation"
}],
"target": [{
"source": "https://www.aihw.gov.au/reports/cancer/cancer-compendium-information-and-trends-by-cancer-type/report-contents/pancreatic-cancer-in-australia",
{
"type": "XPathSelector",
"value": "/form[1]/div[4]/main[1]/div[3]/div[2]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/p[3]",
"refinedBy": {
"start": 0,
"end": 243,
"type": "TextPositionSelector"
}
}, {
"type": "TextPositionSelector",
"end": 15827,
"start": 15584
}, {
"exact": "In 2013, there were 2,865 new cases of pancreatic cancer diagnosed in Australia (1,490 males and 1,374 females). In 2017, it is estimated that 3,271 new cases of pancreatic cancer will be diagnosed in Australia (1,722 males and 1,548 females).",
"prefix": "only diagnosed cancer in 2017.\n\n",
"type": "TextQuoteSelector",
"suffix": "\n\nIn 2013, the age-standardised "
}]
}],
"created": "2017-11-28T18:56:04.889815+00:00",
"@context": "http://www.w3.org/ns/anno.jsonld",
"creator": "acct:judell@hypothes.is",
"type": "Annotation",
"id": "https://hypothes.is/a/yW9M1tRtEee1Q-typwRX4w",
"modified": "2017-11-28T18:56:04.889815+00:00"
}
Here are three key elements:
1. The body. This is the content of annotation. In this example it has two parts. One is empty but, had I written a comment, would contain anything I could write in the Hypothesis editor: plain text, basic HTML (including images and links), math notation. The other contains the tag EnterpriseAnnotation which is the only piece of user-supplied content in this annotation.
2. The target. This is the segment to which the annotation refers. It has a source, which is the URL of the annotated document, and a set of selectors that use different strategies to locate the selection in the document. The most basic of these is TextQuoteSelector which includes the exact text selection, plus the text preceding and following. In many cases that's enough to locate the selection.
But suppose the selection is brown, occurring in the middle of the phrase the quick brown fox. And suppose that phrase occurs several times in the document. The TextQuoteSelector can no longer reliably locate brown in the context of the quick brown fox. In the Hypothesis implementation, two other strategies are available to disambiguate. The TextPositionSelector records the location of the selection within the document. TextPositionSelector doesn't consider HTML tags, only the document's visible text. A third strategy, XPathSelector, records the XPath address of the element containing the selection. Using this repertoire of strategies, an annotation client is resilient not only to ambiguity, but also to change. If a sentence containing a selected phrase moves to another place in a document, the TextPositionSelector and XPathSelector will no longer find it, but the TextQuoteSelector will. And in the Hypothesis implementation it may still be found even if the surrounding context has changed, so long as quote and context stay within a certain Levenshtein distance.
3. The id of the annotation. In the Hypothesis implementation it's the URL of a standalone page that presents the annotation, enables the author to edit and others to reply, and links to the source page and to the annotation's target selection within that page.
In the example above, a page at one government site sources a fact from another site. Ideally that fact would be a managed asset that's stored in an authoritative location and can be reused in other contexts. In practice it's typically copied from one place and pasted into another. In programming terms, it's passed by value instead of by reference. Because nothing connects the two items, the reader can't follow a link from a downstream item to its upstream source. If the upstream source changes, the content management system can't update the downstream copy.
Modern ECM systems encourage the use of modular content blocks, a strategy that makes sense for coarse-grained assets. But to handle paragraphs, sentences, or phrases that way would require authors to anticipate myriad possibilities for reuse, and to invest much effort in preparing for such possible reuse. In an annotation-powered ECM system, every paragraph, sentence, or phrase is a potentially reusable fine-grained asset. Converting a potential asset to an actual one is just a quick select-and-post maneuver.
Today, because we rely on copy-and-paste to surface such assets in new contexts, we lack the ability to maintain consistency and track provenance. A fine-grained asset defined in situ, using annotation, can be linked directly to its original context. It becomes a single source of truth that, when surfaced in other contexts, can be transcluded rather than copied.
Because web annotation happens in overlays that refer to web documents but don't belong to them, the scope of this kind of granular asset management is global and can take silo-busting to a new level. By standardizing on Acquia, Australia's growing family of government websites gains the ability to reuse coarse-grained assets across all sites. But what about assets that live elsewhere? Australia's pancreatic cancer site, for example, refers to content hosted by the American Cancer Society. The Australian site can link to pages there, but can't reuse assets defined in a foreign CMS.
Here's another example of the same kind of problem. Last year, Microsoft announced an overhaul of its TechNet and MSDN documentation. The improvements include using Livefyre for annotating pages of documentation, and offering edit buttons on doc pages that invite readers to fork and propose changes to the underlying Markdown content on GitHub. Nice! But Microsoft's GitHub footprint is much larger than the set of documents managed this way. At https://docs.microsoft.com/en-us/outlook/rest/node-tutorial, for example, the instructions say:
The source code in this repository is what you should end up with if you follow the steps outlined here.
The tutorial, which includes copies of snippets from a GitHub code repo, lives in its own separate documentation repo on GitHub. A reader who uses the tutorial's edit button to fork it and propose a change is editing a copy of the snippet in the tutorial's doc repo, not the authoritive snippet in its own code repo. There's no connection between the copy and the original. And because GitHub is a foreign CMS with respect to docs.microsoft.com, Microsoft can't use its preferred annotation system, Livefyre, to receive feedback directly on the authoritative copy of the code snippet.
In a scenario powered by standard web annotation, the same machinery used to annotate selections in pages at docs.microsoft.com could also be used to annotate selections on GitHub. Annotations made in both places could be tracked in a consistent way. And unlike Livefyre's paragraph-level notes, or GitHub's line-level notes, those standard annotations could refer to arbitrary selections: variable names, partial lines, data structures.
The web doesn't know or care about CMS boundaries. Links in content served by an enterprise CMS are promiscuous. They can point to assets within the CMS or elsewhere. But CMS assets live in silos. A federation of sites built on a common CMS platform is still, from the perspective of the web, a silo. Annotations float across silos.
Fifteen years ago, many enterprise architects didn't fully grasp the flexibility and power inherent in the web's native architectural style. Today the benefits of "Internet-scale distributed hypermedia" are much clearer. We design systems that use RESTful APIs to manage sets of linked resources. With the advent of standard web annotation, we can now expand our repertoire of resources to include all the segments that may exist within conventional web resources. The core principles of the web's native architectural style apply equally to annotation-aware applications. Data are organized as sets of resources that are uniformly addressable and interconnected by links. What's different is the increased granularity of this new class of web resource. That's especially relevant for the ECM scenarios discussed here. But standard annotation is nothing less than a fundamental upgrade to the web. It's architecture delivered surprisingly good outcomes. We should expect the annotation-enhanced web to yield more happy surprises.