
This is a picture of Pierre Teilhard de Chardin.
He was an odd character: a Jesuit priest and also a paleontologist. In this 1955 book, called The Phenomenon of Man...

...he imagined a future in which human minds would be linked together to form a cloud of human awareness surrounding the planet. He called this the noosphere, incorporating the Greek word noos which means mind or consciousness.
This was all just an intuition on the part of Teilhard. He really had no clue how such a thing could actually happen.
But not too many years later, another visionary with a much more practical bent showed us how it could.

I'm sure you all know Doug Engelbart as the inventor of the mouse, and as a key innovator of two dominant computing paradigms: the graphical user interface, and the hypertextual web of information.
Of course Engelbart didn't just dream about these things, he actually built them, as many of you have seen if you've watched his famous "mother of all demos" video which, incredibly, is now almost 40 years old.
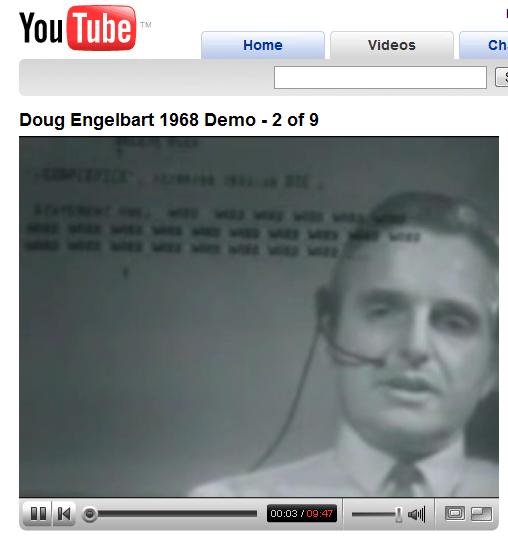
Its amazing how much of what enthralls us today was shown in that demo: the GUI, hypertext navigation, the Skype headset.
What you might not realize, though -- I didn't until fairly recently -- is what motivated Doug Engelbart to do these things. As he explained in a talk at the 2004 Accelerating Change conference, he was, and he still is, on a mission that started one day when he was in his mid-20s, just a few years older than most of you.
On that day, as a young engineer, he suddenly stopped what he was doing and asked himself: Why am I doing this? What is the purpose of this technology that fascinates and compels me?
After wandering around in a kind of revelatory trance for a couple of hours, the answer came to him. He realized that, as a species and a civilization, we were facing serious challenges to our survival.
Now that was sixty years ago, during an era of post World War II optimism, when the limits we're facing today weren't so apparent to most people.
Those limits are a lot more evident nowadays, and our political and economic systems are poorly adapted to deal with them. We need to reengineer those systems, in dramatic ways.
To do that, we'll need to mobilize the collective intelligence necessary to figure out what needs to be done, and the collective will necessary to accomplish it.
So, how do we do that?
Engelbart's vision is crystal clear. It's a vision of human augmentation. We need to augment human capability in certain ways. In particular, we need to create -- and project our minds into -- a shared information space that works like a planetary associative memory.
And we need to populate that shared space with tools that support and amplify and extend our natural ability to analyze, visualize, simulate, decide, and act.
Fifteen years ago that would have sounded nearly as fantastic as Teilhard de Chardin's noosphere. Today, if we look sideways at the web and squint, we can see the picture coming into focus.
But as William Gibson famously said, the future is unevenly distributed. In this case, what mostly isn't here is the part where we come together in shared online spaces, with shared tools and information, to analyze, visualize, simulate, decide, and act -- on a planetary scale.
The good news is that we can hack this problem. I absolutely believe that we can. But we're going to have to hack it at a different level than the one at which the computer and information sciences have historically tended to operate.
Now, the truth is that I am not a born member of the hacker tribe. But as an adoptive son I do know something about the joy -- and the addiction -- of writing code.
In my case, I particularly love to write code that munges semi-structured data. Give me a problem that requires transformation of one flavor of XML into another, and I'm happy to solve it.
So happy, in fact, that I'll go out of my way to look for problems whose solutions can be construed as XML transforms. Sometimes, to be completely honest, after I solve one of those puzzles, I have to stop and remind myself why I tackled it in the first place.
Many of you may recognize this tendency in yourselves. I urge you to notice it, pay attention to it, and reflect on it. Hacking releases endorphins, it feels good, it makes time dissolve, and that's good. In fact, it's great. Provided that you're hacking the right thing, at the right level.
Unfortunately we do have a tendency to hack the wrong things. I guess because we tend to think first, and best, about the protocols that enable machines and applications and services to work together, instead of about the protocols that enable people to work together -- in a context that is defined, but only partly defined, by machines and applications and services.
Ultimately, the right hacks are the ones that help people make sense of their world, and collectively improve it. And the right level is the level of human cognition, attention, intention, and desire.
While we're remembering classic concept videos, here's a clip from Apple's famous late-80s Knowledge Navigator video, which some but maybe not all of you will have seen.
It seems especially relevant today as we contemplate the possibility of catastrophic climate change.
Two things have always fascinated me about this scene.
First, the implicit underlying semantic web of data, which enables different sources of data to align and seamlessly merge.
Second, the idea that data analysis and visualization can be a shared activity, social and collaborative.
Obviously we're still not there yet. What will it take to bring that imaginary scene to life? For a long time I didn't hold out much hope, but recently I've seen some encouraging signs.
In terms of the semantic web of data, progress was stalled for a long time because, in my opinion, we were hacking the problem at the wrong level.
If you follow semantic web technologies at all, you'll have heard about standards and protocols such as RDF, OWL, and SPARQL. And you'll have heard about all the magic that will be released once the world's information is organized into OWL ontologies, encoded into RDF, and queryable with SPARQL.
Unfortunately for the semantic web, people don't want to agree on ontologies, and they don't think in terms of RDF or OWL or SPARQL.
But for a long time, nobody was willing to recognize that inconvenient truth.
Lately, though, there seems to be a new pragmatism emerging, and I'll give you a few examples.

This is my Person record in Freebase, one of a new breed of semantic web applications. When I populated this record, I found that one of the roles I could assign to myself was the role of Author, because I'm the author of a book.
Populating the Author record led me to create a Book record to represent my book.
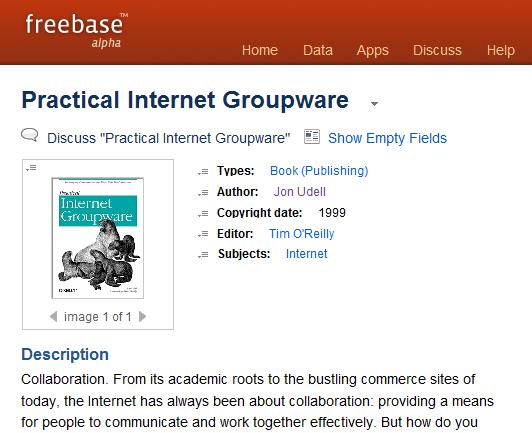
When I filled in the Book record I found that one of the roles I could add to it was the role of Editor. Since it was my excellent luck to have had Tim O'Reilly as the editor of my book, and since Tim had already claimed his person record in Freebase, I was able to assign him to the Editor slot, which was cool.
But even cooler than that was what I saw when I clicked through to Tim's person record.
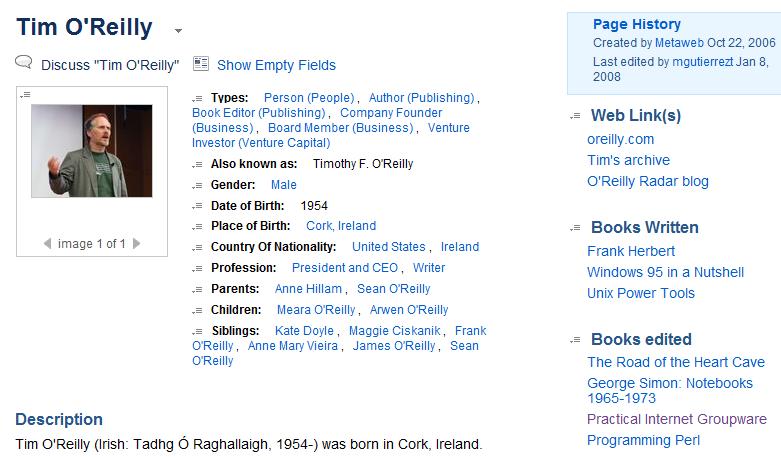
A reciprocal role had been added to that record: Books Edited. And there, in the slot, was my book.
The reciprocal nature of this transaction is a sweet technical hack. But it's an even sweeter and more significant social hack.
Filling in has-a and is-a slots is a pretty dry exercise. But we're all attention seekers, and in an environment where slot-filling maximizes the attention that flows to us, we will be incented to do a good job of it.
The fact that RDF triples (or their moral equivalents) fall out as a by-product -- that's just an incredibly useful side effect resulting from a really clever bit of social engineering.

Here's another example of the same kind of social engineering, also in the domain of the semantic web. Last month I visited with the team at MIT who are working on Project SIMILE, which stands for Semantic Interoperability of Metadata and Information in unLike Environments. These folks have fought the ontology wars, and they've got the scars to prove it. Some of them have spent years in committees trying, and failing, to hammer out agreements about ontologies and taxonomies.
In the end they concluded, correctly in my view, that people model the world in their own ways, for their own purposes.
When we use language to describe our world, it's an organic process.
We speak and write what we hear and read, when it suits us, and when it doesn't we invent our own new forms of language.
Other people, hearing and reading those new forms, will adopt them if they suit their needs, or else they won't.
If you're a podcast listener, or even if you're not, you should hear Erin McKean's 2006 Pop!Tech talk, which is entitled ALL YOUR TEXT ARE BELONG TO US.
She's a lexicographer, she works for the Oxford English Dictionary, and one of her pet peeves is that people think dictionaries are prescriptive, that they tell us which words are better to use than others.
But of course dictionaries don't do that. Dictionaries are descriptive. They chart the evolution of language as we all continuously create it.
That's the stance that the Project SIMILE folks have taken. They decided to give people the tools to create and use their own languages of data. One of their tools is called Exhibit, and it makes web pages that look like this one.
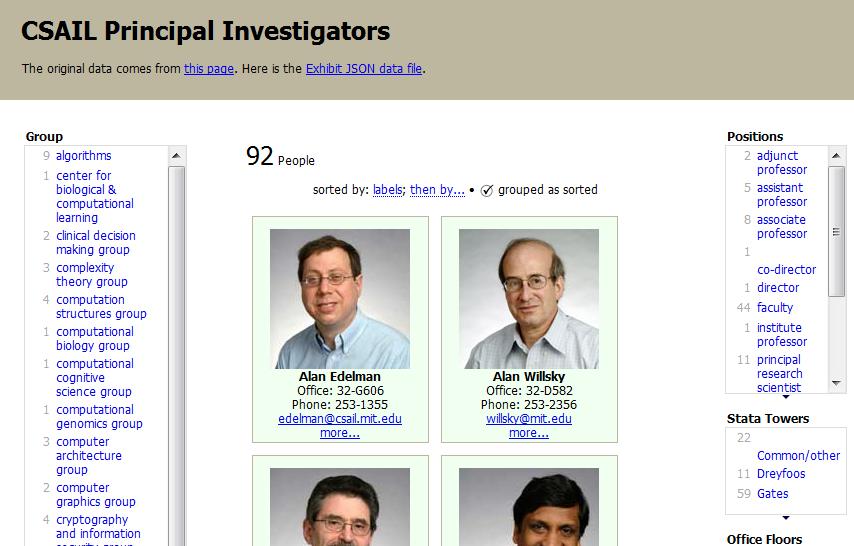
It's based on a data set that descrdibes the faculty of CSAIL, MIT's Computer Science and Artificial Intelligence Laboratory. If you view source on the page, you'll see two JavaScript includes.
One of them sources the data, which is in a JSON -- JavaScript Object Notation -- format that corresponds to a simplified, flattened form of RDF.
The other one sources the behavior of the page: faceted browsing, sorting, filtering.
There's not much else there, just some CSS styling and some DIV tags that bind to the data. It's a page that says: View my source, clone me, modify me.
And so the folks at the Columbia Center for New Media Teaching and Learning did. Here's their faculty page.
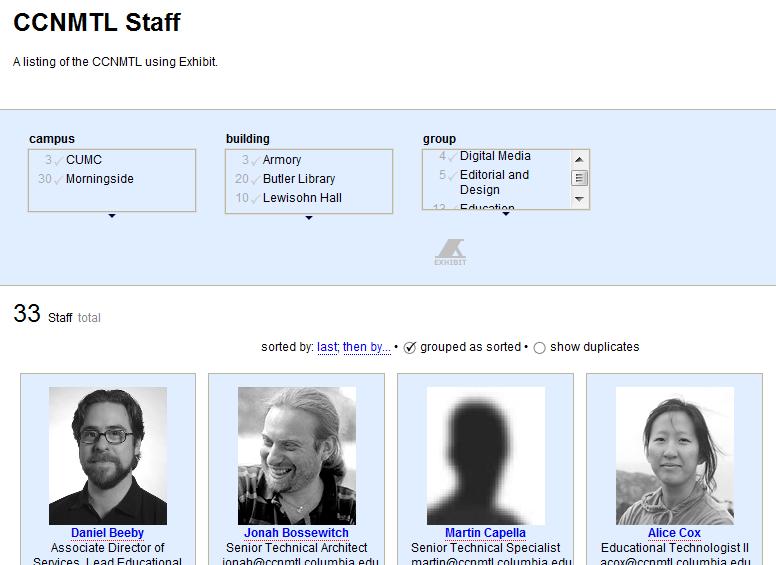
The presentation is slightly bit different. And so, actually, is the data. The Columbia data set removes some of the slots that are in the MIT data, it adds others, and in some cases it calls analogous slots by different names. At MIT, for example, a faculty member has a title. At Columbia, it's a position.
The Simile team has learned the hard way not to haul everybody into a meeting to decide which term will be the standard. They don't care! It's all relative!
And the reason they don't care is that they have cleverly, under the covers, standardized on something more fundamental: a flexible -- and mixable -- data format.
The vocabulary can differ from one data set to the next, and that's fine. In fact it's great, because people want and need to express things in the ways that make sense to them.
But on a deeper level the data files are compatible. It's easy to make equivalences between, say, title, in the MIT data, and position, in the Columbia data.
Going a step further, the amazing David Huyn -- who is responsible for many of Project SIMILE's innovative web applications -- has created a tool that almost anybody could use to make those equivalences.
You open up two or more Exhibit data sets, you drag common fields onto a new column and rename them to make equivalences, you drop fields onto another part of the canvas to create browsable facets, it's a beautiful thing.
There's even a feature called simultaneous editing, done all in AJAX, that lets you parse and rewrite whole columns interactively without ever seeing a regular expression.

It's a technically sweet hack but, again, the even sweeter hack is the social one.
We're all chimps when you get right down to it. We learn by watching what the other chimps do, and then imitating those behaviors. Termite stick? Wow, great idea! I'm gonna make myself one of those!
In this case, the termite stick is MIT's slick faceted browser for faculty information pages. When the Columbia people saw that, they had to have one too. So they cloned it, with modifications, but that was OK, because the underlying data is compatible, and anybody can come along and stitch it together -- like I did here.
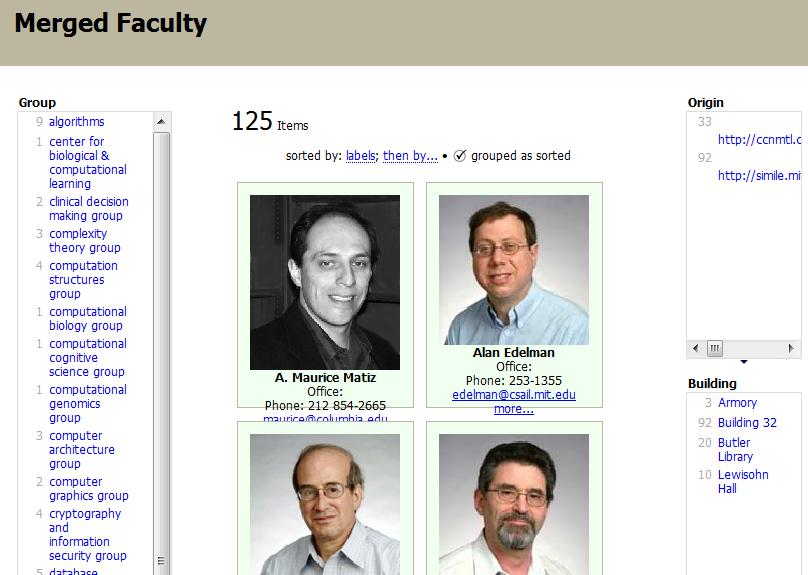
Now I don't mean to turn this into a talk about the semantic web. That is one key aspect of what it will mean to hack the noosphere, but what I'm really trying to draw attention to, in the examples of Freebase and SIMILE, is a design pattern, for information and communication systems, that puts people first, recognizes human desires and talents, and optimizes for collaboration.
So now I'll shift gears and talk about two examples, from my own experience, that have given me some insight into what it means to optimize for collaboration.
The first example is a project I call LibraryLookup, and the second one is the technique now known as screencasting.
LibraryLookup started five years ago when I realized I was over-utilizing Amazon.com and under-utilizing my local public library's online catalog. If the book I want to read is available in my local library I can read it for free, and I can get hold of it sooner than any online bookseller can ship it to me.
I wrote a little JavaScript bookmarklet that I think of as a lightweight client-side service broker. If you're visiting a web page about a book, and its URL contains an ISBN -- this is true for Amazon, for Barnes and Noble, and for some other sites -- the bookmarklet grabs the ISBN, forms the URL that queries the library for that ISBN, and redirects to the library page.
I started with my own local library. Then I realized this would work for any other library using the same catalog system, so I found a list of those and made a page of bookmarklets for patrons of those libraries.
Then I started to hear from librarians who were using different catalog systems. In cases where these systems could do the same kind of ISBN query, I created bookmarklets for them.
At some point, I found some long lists of libraries using each of these types of catalog systems, and I transformed those lists into bookmarklets so patrons of any of these libraries could visit the page and drag-install a bookmarklet.
After a while these lists became unmaintainable. There got to be more and more libraries for each type of catalog, and there got to be more and more types of catalogs. I didn't want to be the central clearinghouse for bookmarklets, so I created a bookmarklet generator that people could use to instantiate a bookmarklet for a known catalog type.
Meanwhile, during the period when all this was happening, the industry went through its initial wave of interest in SOAP web services, followed by the contrary wave of interest in RESTful web services.
I'm agnostic when it comes to this stuff. I see lots of value in both approaches, and I believe that a best-of-both-worlds strategy makes sense.
But LibraryLookup did produce a key insight about the RESTful approach. And it's especially significant because this insight didn't come from me, it came from a non-technical librarian who was trying to make LibraryLookup work with her catalog.
To this day, I hear regularly from librarians who want to know if LibraryLookup "supports" their online catalogs. What does it mean for a catalog to "support" LibraryLookup? Nothing much, really. You just have to be able to form a query, on the URL-line, that includes an ISBN and reports the availability of a book.
Most of the catalog systems will do that, but there are a few that won't, for one reason or another -- because the application only accepts a GET, not a POST, or because it require the user to be logged in, or whatever.
This librarian's system is one of the types that isn't friendly to LibraryLookup. When I explained that to her, she said the following amazing thing:
"Oh, I get it," she said, "we bought the wrong kind of software."
Now she did not understand, as you all do, that "the wrong kind of software" means something like: "a web application that is not RESTful, and does not provide affordances for both programs and people to do lightweight, opportunistic integration."
But unlike the programmers who created that online catalog, and the IT folks who bought and installed it, she understood very well that if she couldn't get it to work with LibraryLookup, the fault lay with the software and not with her.
Meanwhile, I'm constantly hearing from librarians who are lucky enough to have the right kind of software, and who are excited to be able to figure out how to hack their catalogs' URLs in order to get LibraryLookup to work with their systems.
I've gotten a bunch of emails like this one from Janet Lefkovitz at the Hebrew University of Jerusalem:

I love to encourage and reward these efforts, so I credited her with the discovery:
At this level of the stack, service integration winds up being a game of capturing, analyzing, rewriting, and stitching together URLS.
What I've found is that although a lot of librarians have never played this game before, they are quite capable of figuring out how to do it. And when they succeed, they're thrilled to have created something that empowers other people.
Of course all this flows naturally from the architecture of the web. If two RESTful applications share a common piece of metadata, like an ISBN, it's just a given that you can stitch them together.
The programmers who created the online catalogs that work with LibraryLookup didn't have to do anything special to "support" LibraryLookup, they just had to avoid screwing it up by preventing people from accessing the URLs they could latch onto and use in unintended ways.
But what if they had thought about encouraging unintended uses? As programmers we're all familiar with the API design pattern. Of course it would be great if the designers of these online catalogs had thought to provide APIs, and it would be even better if they got together and agreed on a common API like the one that John Blyberg, a systems librarian with the Ann Arbor Public Library, has proposed.
We think a lot about creating APIs to empower other programmers. We don't think nearly enough about creating HPIs -- human programming interfaces -- to empower the Janet Lefkovitzes of the world.
I've always argued that web namespace is one important kind of human programming interface. URIs should be built on clear, simple, and predictable patterns that make sense to civilians as well as to programmers. There's a classic style guide for writing clearly in English, it's the famous book called The Elements of Style, by Strunk and White.

There isn't yet a Strunk and White for URI design, but the recent book RESTful Web Services, by Sam Ruby and Leonard Richardson, does touch on the subject.

For example, they recommend that when you are designing URIs, you should use forward slashes to encode hierarchy (/parent/child), commas to encode ordered siblings (/parent/child1,child2), and semicolons to encode unordered siblings (/parent/red;green).
This matters not only because a web application's namespace is an API for developers, but also because it's an HPI for everybody else. People are hardwired for language. They can internalize rules and patterns, and generate new things basd on them. As developers we ought to be finding ways to leverage that language instinct.
Instead, we tend to hide or obfuscate web namespaces. Why? We assume people don't want to read, or heaven forbid write, complicated URLs. And of course they don't. But they are perfectly capable of reading and writing simple and sensible URLs.
If you want to see this happening in real life, just look at folksonomies. When people use tags, they're creating new web namespaces.
Admittedly, the rules are vague. There's no Strunk and White for tags yet. So when people move from site to site things get confusing. Unordered siblings may be encoded using spaces, commas, semicolons, or other delimiters.
But that's exactly my point. Formalizing those rules and patterns isn't just a pedantic exercise. It's a kind of social hack that could help us tap into people's collective ability to synchronize their use of named resources, create new named resources, and do lightweight, opportunistic integration by composing sets of named resources.
Switching gears again, I want to talk about screencasting because it can be another really powerful tool for hacking the noosphere. For example, I know there are a lot of Rails hackers in this crowd, and my guess is that more than a few of you got turned onto Rails when you saw that original screencast showing how easy it was to build a blog system in Rails.
I have a theory about why this medium can be so effective. Think back to that band of chimps watching one of its members learn out how to use a termite stick. With humans, as with chimps, it's monkey see, monkey do. We learn by watching and imitating. For most of human history, humans learned how to use tools by watching other humans use those tools, then copying the behavior.
But it's a funny thing. Although we feel hyperconnected in the era of networked communication, it turns out that we have surprisingly few chances to watch and imitate how other people use their software tools and information systems.
When we're sitting side by side, we can look over each others' shoulders, and watch, and learn. But for decentralized teams, voice and text are still the dominant modes of communication, and they don't enable that same kind of direct transfer of knowledge and experience.
Screensharing can mediate that direct transfer synchronously, in realtime. For that reason, I think it's critical for us to get to the point where it's just as trivial to share screens and keyboards remotely as it is to set up a text or voice session.
One reason why this matters has to do with tacit, or unconscious, knowledge. Things we know how to do, but don't really know that we know, and can't articulate or explain.
Here's a good example from a screencast I recorded with Jim Hugunin, the creator of Jython and more recently IronPython.
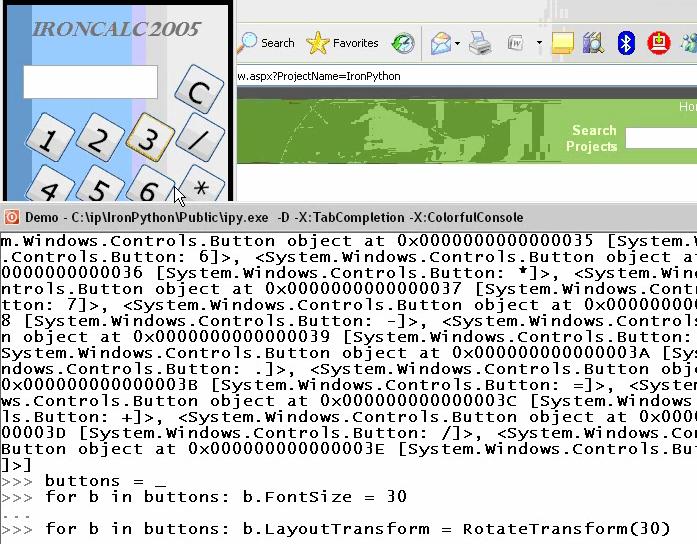
Here Jim was showing me how IronPython lets you dynamically hack the Windows Presentation Foundation. But when he used the underscore variable, he taught me something about Python that I hadn't known, even though I've also been a Perl hacker, which is that in Python the most recently evaluated expression lands in the special underscore variable just like it does in Perl.
For Jim, this is unconscious knowledge. He used the underscore variable without even thinking about it.
For me, it was a revelation. For about 10 seconds, while Jim was going along with his demo, I was thinking: "Wow, Python uses underscore just like Perl does."
And what's interesting is that although Jim taught me that, he doesn't know that he taught me that. The knowledge was transmitted directly and, from his point of view, unconsciously.
My guess is that this kind of unconscious knowledge transfer has a lot to do with the effectiveness of pair programming. Watching your partner using software tools, you absorb knowledge that he or she may not even be aware of, and doesn't -- maybe can't -- communicate explicitly.
If realtime screensharing were ubiquitous and dead simple to use, we could extend these knowledge transfer effects across the Net. And not just for programmers. There's a much bigger opportunity for users to connect with other users, share what they know about working with software and information systems, and learn from one another.
Of course realtime screensharing doesn't scale, for the same reason that other synchronous modes of communication like voice and text chat don't scale.
That's why screencasting, which is the asynchronous form of screensharing, is so interesting. You record something once, like the Rails screencast, then it can scale out and reach a lot of people.
The best example of this, in my own experience, is the so-called Heavy Metal Umlaut screencast, which charts the evolution of Wikipedia's page about the use of the umlaut in the names of heavy metal bands.
The fact that such a Wikipedia page exists is delightfully silly, but the screencast turned out to have a serious and far-reaching effect. For years before that, I'd been trying to explain to people how wikis work, and in particular how the culture of Wikipedia seems to magically defy entropy and produce order out of chaos.
But nothing that I said, and nothing that I wrote, could make the light bulb go on in people's heads. You had to actually experience Wikipedia in order to really get what Wikipedia is about.
While the screencast doesn't actively engage people in that experience, it does convey, in a fairly immersive way, a strong sense of what it's like. People who watch it say: "Oh, OK, now I get it." The light bulb clicks on in their heads. In fact, the educational effect has proved to be so powerful that I've noticed a number of college instructors now include this screencast in their syllabi.
The best screencasts are social hacks that break through the barriers that stop people from properly understanding and effectively using software and information systems.
As technologists, we tend to assume that what holds people back is our failure to invent the right mix of features, or to wrap a sufficiently user-friendly interface around that mix of features.
And sometimes that's true. But not always.
Sometimes the barriers are purely conceptual. Sometimes it's not about the features, or even the interface, it's only about the ideas people do or don't have in their heads about the ways we can communicate and collaborate online, or about the kinds of online social and cultural environments we can create and inhabit.
Wikipedia's a great example. Although MediaWiki is a powerful piece of software, it isn't Wikipedia's core innovation. Another wiki implementation arguably could have produced the same effects. The core innovation lay not in the software hackery, but in the social hackery that produced the agreements and protocols and traditions that are what really make the whole thing work.
Another example, one that happens to be Montreal-based1, is LibriVox, the collaborative project to make audio recordings of public domain books.

For quite a while the whole project ran on nothing fancier than an online bulletin board. A lot of us here, me included, would have been tempted to write a soup-to-nuts database-backed application to support that project, because that's what we're good at, and that's what we like to do.
But when I saw how the project really works, I realized that would have been a mistake. Like Wikipedia, LibriVox is actually powered by a set of agreements and protocols and traditions. You can imagine encoding those in software, and the project's founder -- Hugh McGuire -- might have wanted to, if he'd had access to the right kind of software talent. But he didn't, which was almost certainly a good thing. Because the agreements and protocols and traditions weren't known ahead of time, they had to emerge from the collective. As it turned out, a bulletin board -- with its weak structure and loose coupling -- was exactly the right way to nurture that emergence.
Over time, those loose structures have begun to coalesce. There's a database behind LibriVox now, but the project still doesn't feel like a database application, it's more like a bulletin board that's been enhanced with some database features. The real innovation continues to be in the agreements and protocols and traditions that attract, reward, and sustain contributors. LibriVox is a success not because of any particular bit of technical hackery, but because of Hugh McGuire's inspired social hackery.
Now, it's always a good idea to suck up to the conference organizers. So I'll end by noting that this conference is yet another example of an inspired social hack. The instincts that brought this together were really good. Trust those instincts, and let them take you as far and as wide as they can.
1
Hugh McGuire adds:
LibriVox is not really Montreal-based … it lives independently on the web, and its only Montrealness is me, and the odd chapter & volunteer efforts from other Montrealers. Also, while I may have instigated some inspired social hackery, there sure were and are a lot of people equally inspired.