
As we colonize the cloud we'll want to mix and match web services in order to meet our needs. To do that it's helpful to analyze what the current crop of services actually do. In many cases, if you stop to think about it, they conflate several different services in ways that are not easy to separate or recombine. Consider, for example, your use of Facebook or Flickr. The services they provide to you include:
Since you have no contractual relationship with Facebook, nor with Flickr if you're not a Flickr Pro customer, none of these is a service in a true sense. But let's call them services anyway, and think about which are core offerings and which are peripheral.
Clearly Facebook and Flickr are personal publishing platforms that socialize your data. Thanks to its robust tagging mechanism Flickr can, additionally, be a really effective tool for cloud-based personal information management, although I don't think many people have yet figured that out.
What about archival storage, though? Most Facebook users, like most users of the free version of Flickr, think of these services as cloud-based archives. Many, I'm sure, have content on these services that exists nowhere else. But of course they're not really archives. No contract requires these services to keep your stuff alive and available a year from now, or a decade, or for your grandchildren.
Archival storage is, in principal, orthogonal to the core services of publication and socialization. I imagine a world in which all my stuff lives in my own personal cloud, which has a contractual relationship with various services providers. One of these provides the service of archival storage. And there are many storage providers to choose from. Some will be free and ad-supported. Some will be cheap, but will offer only a basic guarantee of continuity -- say, 10 years. Some will be expensive but will offer a multi-generational guarantee.
I'll still want Facebook and Flickr to publish and socialize my stuff. How will they do that? By syndicating the stuff from my personal cloud. Obviously that is not something such services are willing and able to do today. But it's a scenario we ought to imagine and work toward.
The elmcity calendar syndication service demonstrates the principle in a small way. If you publish a calendar on a Facebook fan page, it can syndicate to an elmcity hub. For some organizations, that Facebook calendar is the primary and canonical source for that data. Although my service supports that choice, I don't recommend it. Why not? Links to events on that Facebook calendar only resolve for logged-in Facebook users. I think an organization's primary public calendar should live on the open web. So I recommend that organizations manage their own calendars on their own websites, or delegate them to services (Google Calendar, Hotmail Calendar) on the open web.
But you'd still like to socialize your events on Facebook. It's incredibly effective for that purpose. So, consider this event:
It was part of the Ann Arbor Summer Festival. If the calendar on that site offered an iCalendar feed I would regard it as primary. But since it doesn't, I routed the festival's Facebook calendar into the Ann Arbor hub in order to create this HTML view and this corresponding iCalendar feed.
From the perspective of the elmcity hub, the festival's calendar looks like any other inbound iCalendar feed, there's nothing significant about the fact that it came from Facebook. Let's suppose that the festival did publish its own iCalendar feed. The elmcity hub provides a way to route that data into Facebook without retyping it into a Facebook form. Here's how:
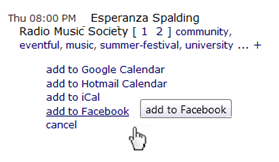
And here's the result:
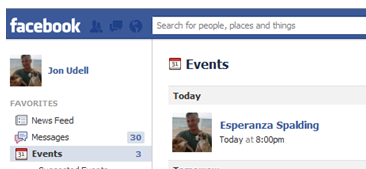
I've done this here with my own Facebook identity, so I've only publicized the event to my own Facebook friends. But the owner of the Summer Festival's page could do the same in order to publicize the event to its fans.
I encourage you to think about your personal cloud as a platform for remixing other services in ways that align with your needs and interests.