
Ten Decembers ago I started a little project called LibraryLookup. It was -- actually, still is -- a bookmarklet you can invoke from an Amazon book page in order to check the availability of that book in your local library. The first version worked with my own local library, the Keene Public Library. And it was possible because the library's OPAC (online public access catalog) could respond to URLs that include ISBNs.
For example, 0765303612 is the ISBN for David Brin's Existence. If you search for that book on Amazon, you'll land here:
www.amazon.com/Existence-David-Brin/dp/0765303612/
See how the Amazon URL includes 0765303612? The bookmarklet takes that ISBN from the Amazon URL and uses it to form another URL that queries the Keene Public Library catalog. Here is that URL:
http://ksclib.keene.edu/search/i=0765303612
If I click it now, here's the result:
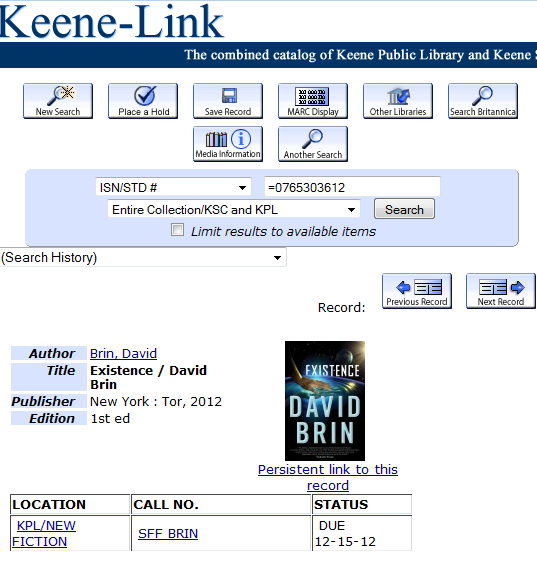
From this screen I can see that it's checked out and overdue. If I want to read the book, I can put it on hold.
That's great if you live in Keene, but what about elsewhere? The first expansion of the idea was to other libraries that use the same Innovative Interfaces OPAC as mine. I made a bookmarklet generator you can use to create a bookmarklet that works with your library's Innovative OPAC.
The next phase of expansion was to other OPACs. And that's where things got really interesting. It turns out that the capability of responding to an URL that includes an ISBN is unevenly distributed. With some OPACs, it's an obvious and easy thing. With others it's not obvious or easy but still possible. And with some you just plain can't do it.
In technical circles this capability is called a RESTful API. But when I talked with librarians around the world who wanted to add their OPACs to my list, we didn't call it that. We just called it "making an URL that does an ISBN query."
One day I was explaining to a librarian that her OPAC couldn't work with LibraryLookup because it didn't support that kind of query URL. Why not? In this case, because the OPAC packaged its interface as what we then called "a rich Internet application" and know today simply as an app. The idea then, as now, was to provide a simpler and more appealing way for people to do things on the web. But the unintended consequence, then as now, was to foreclose options for combining apps with other apps to do new and unforeseen things, like using Amazon's catalog as an interface to your public library.
I'll never forget the librarian's response when I told her this:
So, you're saying we bought the wrong kind of software?
Yup. Sorry, but you did.
Now it's a decade later, we're colonizing the cloud, but people are still, far too often, buying the wrong kinds of software. I still see library OPACs that don't support the simplest, most basic kinds of integration with other systems.
In my current effort to bootstrap networks of interoperable community calendars I see a similar thing. Countless websites use homegrown or commercial content management systems to post their public calendars. The vast majority of those calendars live in siloes because they don't implement the 14-year-old Internet standard for calendar exchange. When I ask developers and vendors why not, they tell me: "Customers aren't asking for it."
So here's the deal. Ask. When you're evaluating a cloud-based application or service, as you will often be doing from now on, ask whether its developer has prepared it to work with other applications and services in the cloud. That might mean a formal API. Or support for the relevant Internet data-exchange standard. Or a data import/export feature. Or sensibly-designed URL patterns. Or all of these things.
Please ask. If you don't, you may someday realize you bought the wrong kind of software. And in a world that's increasingly connected, or anyway should be, we will all suffer the consequences.