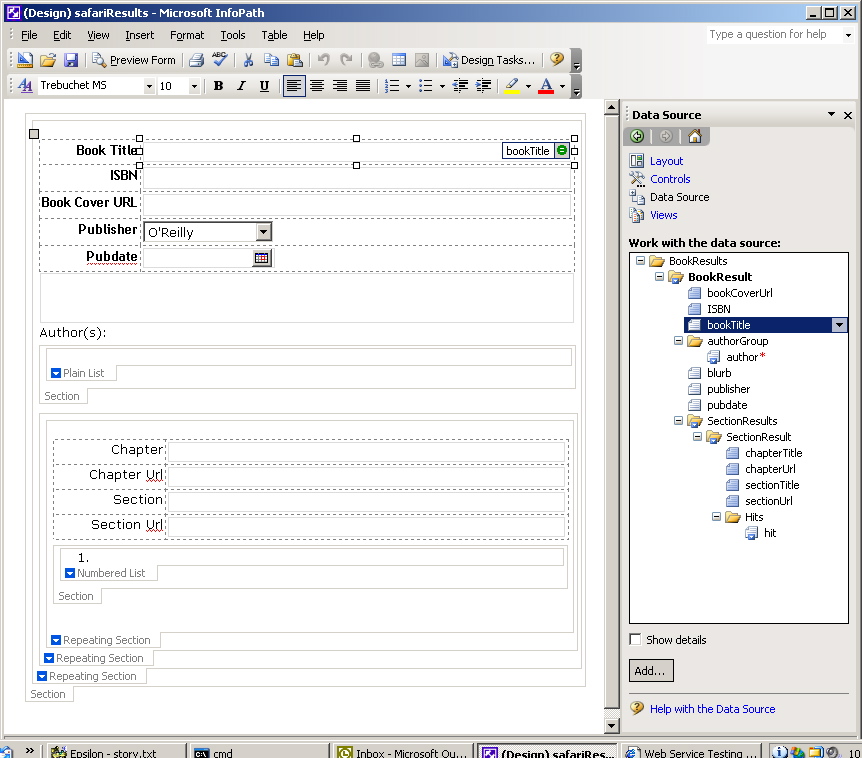
InfoPath in design mode

Gathering XML data
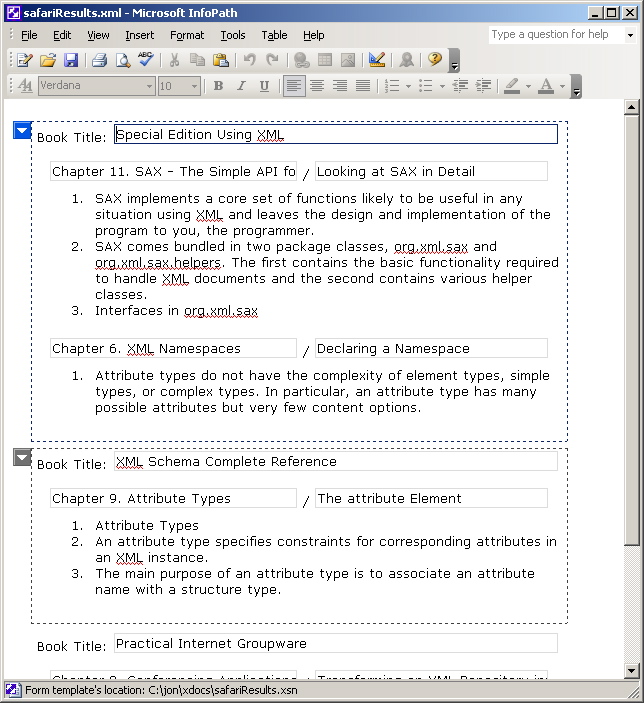
A streamlined view of the
data
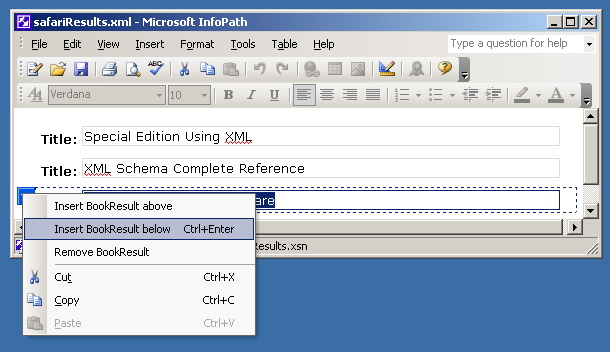
A minimal view of the
data
|
InfoPath in design mode
|
|
Gathering XML data
|
|
A streamlined view of the
data
|
|
A minimal view of the
data
|
InfoPath generally met my expectations, which were high. My two main criticisms were the weakness of the XHTML editor, and the disconnect between validations applied using InfoPath wizards and validations expressed in the XML schema. I had a long talk with Jean Paoli the other day about both of these points.
Regarding the XHTML editor, Jean confirms that it is, indeed, derived from the DHTML editor, and so inherits its HTML-generating pathologies. To see why I harp on this point, consider my experience with Radio UserLand. At one time, I saw the DHTML editor embedded in the Windows version of the product as a key selling point. But after mounting frustration I finally had to abandon the cursed thing. I am writing these words in XHTML, by hand, in emacs, and while that is not as crazy as it sounds -- it ain't rocket science, really -- it is absurd that there's no capable and widely-standardized alternative.
For InfoPath, Jean says, the goal was to stress the macro-structure of documents -- which InfoPath handles brilliantly -- rather than their micro-structure. And it's true that if you only use the XHTML editor to type brief snippets, its pathologies are not so obvious. But from my perspective, it's relevant and useful to include substantial chunks of styled text -- perhaps with embedded tables and images -- almost anywhere. We've been told to expect a universal canvas, and that's just what I do expect. Free text need not, and should not, be schema-controlled in a highly granular way. But please, can't it be cleanly formatted, reusable, and friendly to strategies like XPath search?
Regarding validation, Jean pointed out -- as I hope I also made clear -- that InfoPath will validate against an arbitrarily complex schema. One thing I didn't point out is that, if you feed an existing complex schema to the form designer, it will "sniff" the structures and map them to appropriate GUI widgets. The idea here is that IT-created schemas already exist in the world, and InfoPath is making it easy for people to latch on to them and work with them. That's one major use case.
A very different use case is the one I focused on: a user builds a form from scratch, begins collecting data, distributes the form to other users who also collect data, and then everyone (including IT!) learns, in an iterative and exploratory way, what kinds of data are needed. InfoPath supports this use case too, and I find that really exciting. My hunch is that this case is important enough to warrant more aggressive translation of wizard-generated rules to the schema. But in truth, Jean doesn't know how users will react to this amazing new tool, and neither do I. It's going to be fascinating to watch!
Former URL: http://weblog.infoworld.com/udell/2003/03/29.html#a651