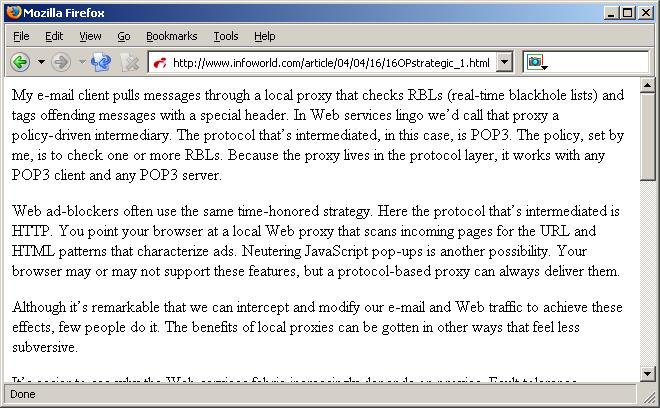
One of these years, my bank will upgrade to a new system that's built around Web services. They'll probably offer a basic "rich Internet application" -- for Windows, Java, or Flash -- that connects to those services. When the bank announces the upgrade, it will stress the richer user experience and choice of interchangeable clients.As mentioned in this week's column, I've been experimenting with a local Web proxy that XHTML-izes and transforms Web pages on the fly. Here's an example:
Those will be crucial benefits indeed. What won't be said, because it's harder to explain, is that the system will also have become radically extensible. Suppose I want to trigger an alert when a transfer exceeds some limit or when a duplicate amount appears. Today, if the system doesn't implement these rules, I'm stuck. In a services-oriented environment, though, I needn't depend on either the bank or my client software. If neither delivers the features I want, I'll inject an intermediary that does. Local proxies are geeky curiosities today, but someday we'll wonder how we lived without them. [Full story at InfoWorld.com]
In this screenshot, Firefox is pulling this week's InfoWorld column through a proxy based on the one included in the Twisted framework for Python. Inside the proxy, I'm using mxTidy to convert the text of the page to XHTML. Then I'm using libxml2's XPath search to find just the paragraph elements with the class attribute ArticleBody, and rewriting the page to include only those elements.
It's kind of a parlor trick, I'll admit. But realtime XML transformation of Web pages could have applications that go way beyond ad blocking. Suppose I store all my XML-convertible Web content in an XML database. (Some stuff can't be XHTML-ized, but it turns out a lot can.) It's just text, after all, I bet a year's worth of content is a drop in the bucket compared to a typical MP3 collection.
Given such a database, the on-the-fly filter could do some clever correlation. Suppose that for the pages I read -- and maybe also for each link in those pages -- the filter extracts URLs, queries the database for elements that mention those URLs, and rewrites the current page with links to the query output. Voila! Instant context.
I don't yet know if this will be practical, and in fact my XML.com column is late this month because I haven't figured that out yet. But it's an exciting idea. We have a surplus of storage and processing power on the desktop, but never enough useful context. When more of our data flows are XML, local proxies will really shine. Even now, though, they can do more than you might think.
Former URL: http://weblog.infoworld.com/udell/2004/04/19.html#a977