In the early days of XML, smart search was often cited as a key benefit. Instead of just trawling for single-celled keywords in an ocean of undifferentiated text, the story went, we'd navigate islands of structure looking for more evolved creatures. Product descriptions, calendar events, and media objects are all examples of the kinds of things we were meant to be finding by now.
That vision hasn't materialized yet, but I'm not ready to give up on the idea. A year ago I wrote about my efforts to chart "a middle course between the Scylla of simple full-text search and the Charybdis of unwieldy tagging schemes and brittle ontologies." The Scylla of this myth was Google's Sergey Brin, and the Charybis was the W3C's Tim Berners-Lee. Between Brin's "we don't need no stinking structure" and Berners-Lee's "wrap everything in RDF (Resource Description Framework) and OWL (Web Ontology Language)," there is a vast, fertile middle ground awaiting discovery.
...
Of course, some tags are implicitly woven into the fabric of our content. Consider, for example, the recent Demo conference in Scottsdale, Ariz. As information about the event flowed into the blogosphere, a likely tag to hang on conference-related items would have been the distinctive name Demo@15. And sure enough, that tag was used on both Flickr and del.icio.us, although by only one person1. (Hint to conference planners: If you want the blogosphere to synchronize its coverage of your event, pick a tag and promote it.)
But there are also implicit tags -- for example, links -- that identify items about the conference, and a new service I built this week is helping me find them. After Jason Hunter showed me Mark Logic's Content Interaction Server in a screencast, I set up an instance of it and began pumping in the RSS feeds of all the blogs I read. Then I wrote a query that combines free-text search for items containing the strings "Demo" or "Demo@15" with structured search for items that contain links to demo.com. It yielded a nice list of Demo-related items that I couldn't have built any other way.
The service works by converting the HTML content of my feeds into well-formed XHTML, storing it in the Mark Logic database, and then using the XQuery engine to perform hybrid free-text and structured searches. Although the vocabulary of XHTML is not very rich, certain elements -- notably links -- carry a latent semantic payload.
It's also possible to enrich the semantic payload of blog content, and on my own blog I've been doing that for a while. Using my local XPath query service, you can easily find quotes by Ward Cunningham, Python code fragments, and a number of other things I'm marking with simple CSS tags. Can these ad hoc syntaxes be collaboratively extended? If we can get structured search working for the whole blogosphere, we'll find out. [Full story at InfoWorld.com]
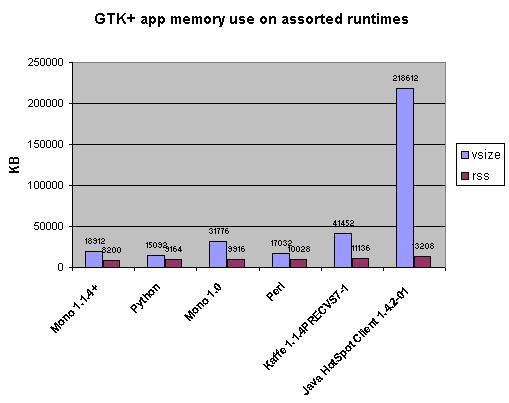
Amidst all the screencasting excitement, I've been continuing to explore this area. Here's a fun little example. I remember that a while back, on Miguel de Icaza's blog, I saw a table that compared memory use for a simple GTK+ app on a variety of runtimes -- including Kaffe. Will this query find it? Yep. For future reference, let's nail that down a bit more precisely as this query. Now let's chart that data:
How'd I get there? Via this query, which converts the XHTML table (that I made from Miguel's HTML table) into row-normalized XML.
As Kingsley Idehen notes, I have been a tireless collector of these kinds of examples. Danny Ayers finds the approach interesting, but flawed and brittle. Adrian Cuthbert sees an interesting connection to the AutoLink debate.
Where's it all headed? Beats me. I'm just following my nose.
1 Actually the demo@15 meme did later gain traction on del.icio.us.
Former URL: http://weblog.infoworld.com/udell/2005/03/01.html#a1187