I had a fascinating conversation the other day with Bob Wyman, the CTO and co-founder of PubSub.com. PubSub's game is "prospective search" -- watchlists, in other words. You plug in search terms; PubSub compares them to the new content it sees; it alerts you when things match, via RSS or XMPP (Jabber). The obvious application is ego-surfing: watching reactions to your own name, your company's name, your product's name. But PubSub differs from, say, a Technorati watchlist, in its commitment to speedy notification of a match. Time-sensitive matches can be reported in just a few seconds, Bob says. In this case the delivery mechanism of choice is XMPP, and PubSub offers sidebars for Firefox and IE to receive these realtime alerts. I'm not usually in that much of a hurry, but plenty of folks are: traders, for example, whose antennae quiveringly anticipate the next scrap of market-moving news.
PubSub currently tracks an eclectic set of datatypes: blogs, newsgroups, press releases, earthquakes, airport delays, EDGAR filings. In the case of blogs and newsgroups, you just try to match text strings. But in other cases it's a bit more structured. You match EDGAR filings by CIK (central index key) code, airport delays by city or airport code, earthquakes by region and magnitude.
If you've followed my work you'll know that my next question was: "What about structured search of blogs?" Bob's been thinking about this too, and his skunkworks effort is called structuredblogging.com. I found it so intriguing that I set up my first instance of WordPress just to try it out.
My strategy has been to weave semantics directly into ordinary XHTML using CSS class attributes. Bob's approach embeds a separate slug of machine-readable XML. I think either of these could work, so long as it's easy for people to write the stuff. And that's where StructuredBlogging's WordPress plugin shines.
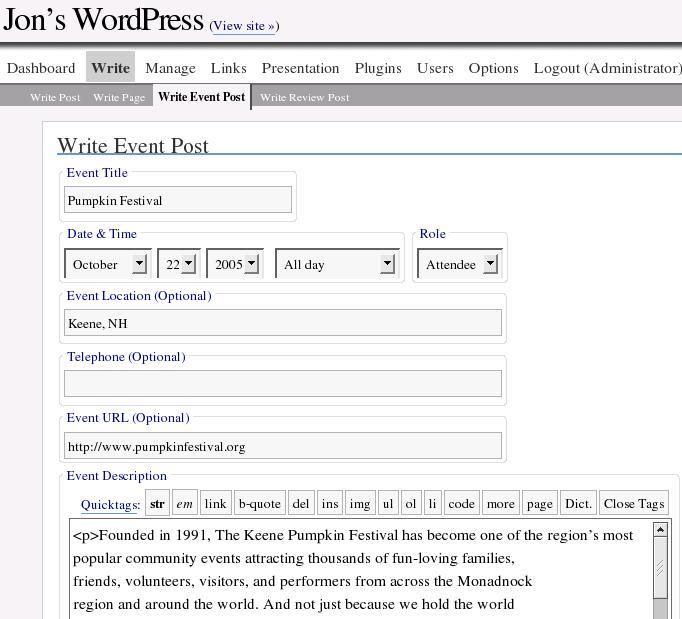
Here's a plugin-controlled template for an event:
Here's the published representation of the event:
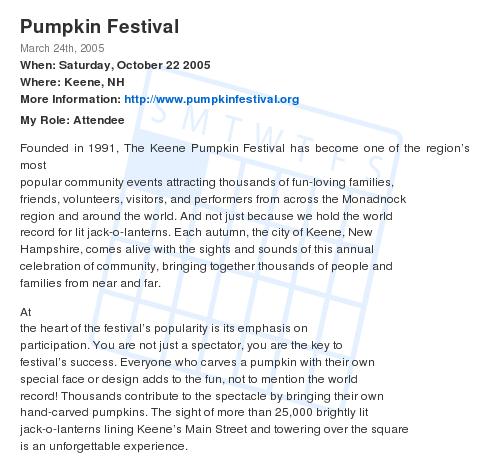
It's hard to see in this rendering, but the style of the entry includes a background image of a calendar. This visual branding isn't just a detail, it's a central aspect of the strategy. If we ever get a virtuous cycle going around this stuff, it'll only happen because people see things they want to imitate. Appearance matters.
And here's the embedded XML:
<script type="application/x-subnode; charset=utf-8"> <!-- the following is structured blog data for machine readers. --> <subnode alternate-for-id="sbentry_1" xmlns:data-view="http://www.w3.org/2003/g/data-view#" data-view:interpreter="http://structuredblogging.org/subnode-to-rdf-interpreter.xsl" xmlns="http://www.structuredblogging.org/xmlns#subnode"> <xml-structured-blog-entry xmlns="http://www.structuredblogging.org/xmlns"> <generator id="wpsb-1" type="x-wpsb-simple-event" version="1"/> <simple-event version="1" xmlns="http://www.structuredblogging.org/xmlns#simple-event"> <datetime>2005-10-22</datetime> <event-title>Pumpkin Festival</event-title> <location>Keene, NH</location> <role>Attendee</role> <more-information url="http://www.pumpkinfestival.org"/> <description type="text/html" escaped="true"><p>Founded in 1991, The Keene Pumpkin Festival has become one of the region's most ... </description> </simple-event> </xml-structured-blog-entry> </subnode></script>
These strategies tend to bog down in geeks-dancing-on-the-head-of-a-pin debates about XML formats. I urge everyone even remotely interested in this idea not to go there. Focus, instead, on the user experience. I want to blog an event; when published, my event should have a certain look; my writing software knows how to produce that look; I'll use it to achieve that look. I don't know, or particularly care, that machine-readable content comes for free. I will, however, be pleasantly surprised when I find that the Net does intelligent things with my event postings: aggregates them with others that share the same venue or date, syndicates them into upcoming.org.
It might be nice to have a single agreed-upon format, but the key thing is to get bloggers to pump structured microcontent onto the Net, period. For those of us who'll aggregate the stuff, sorting out differences will be a headache but not a showstopper. Hell, we have 7, or 9, or some crazy number of RSS formats, and yet somehow the blogosphere keeps churning. Brokering the differences among multiple microcontent formats for events, reviews, how-to's, and other content types would be a good problem to have. At least we could identify the types. That's huge.
Former URL: http://weblog.infoworld.com/udell/2005/03/24.html#a1201