When fact-checking organizations investigate claims, they publish their findings in two interwoven formats. An article online at Politifact, Snopes, FactCheck.org, or the Washington Post is, of course, a web page read by human beings. Nowadays, that same web page is also likely to contain information read by crawlers at Google and Bing. Why? Consider the following claim:
"Forty percent of Americans under age 35 tell pollsters they think the First Amendment is dangerous because you might use your freedom to say something that hurts somebody else’s feelings."
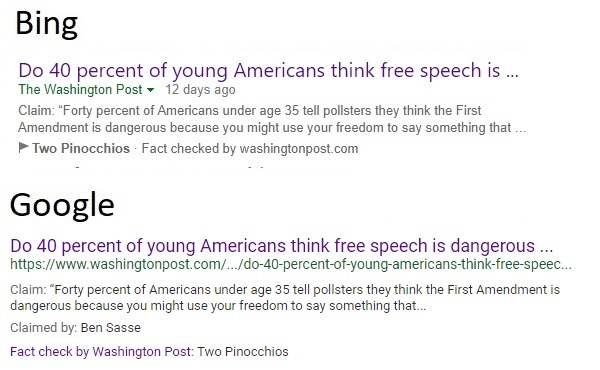
Senator Ben Sasse made that claim in the April 10 hearing with Mark Zuckerberg. The Washington Post evaluated it and rated it Two Pinnochios. If you search Bing or Google for the claim, that Washington Post story unsurprisingly shows up first. You might be surprised, though, to see some extra labeling on the search results.
The fact-check labels attest to the credibility of the source of the fact-check (e.g., Politifact), and summarize the verdict. That's really helpful, especially when you consider variants of the claim that people might search for. Here are some queries that find the same Politifact article:
expand pre-k to all of New York's children
cuomo pre-k for 4-year olds in new york
universal full-day pre-k new york
These labeled search results are signposts that help us navigate a bewildering information landscape. Where do the labels come from? They're included in machine-readable metadata that's embedded in fact-checking articles. When Bing and Google crawl that Politifact article, they find a chunk of ClaimReview data that includes:
{
"claimReviewed": "Four years after Gov. Andrew Cuomo promised universal pre-K, \"79 percent of 4 year olds outside New York City lack full day pre-K.\"",
"itemReviewed": {
"author": {
"name": "Cynthia Nixon",
"jobTitle": "Candidate for New York Governor",
}
},
"reviewRating": {
"alternateName": "Mostly True",
"ratingValue": "5",
"bestRating": "7",
"worstRating": "1"
}
}
Search engines associate this data with the URL of the fact-checking article, and use it to label the article when its URL shows up in search results.
So far, so good. But more information could be conveyed. For starters, we are missing a key datum, the URL that points to the target of the claim itself. That URL might point to a web page or a video; in this case it's a video.
(More specifically the target isn't just the video, it's the segment of that video in which Cynthia Nixon makes the claim that Politifact checked. See Open web annotation of audio and video for more on how we can annotate the targets of claims when they appear as audio/video segments rather than as selections in text.)
But claim reviews should at least cite the appropriate target document or video. Often they don't. For example, in Cold Facts on the Globe's Hottest Years, FactCheck.org evaluates this claim:
Temperature increases for the likely hottest years on record (2014, 2015 and 2016) are "meaningless" because they are "well within the margin of error."
Here's the ClaimReview data embedded in the article:
{
"claimReviewed": "Temperature increases for the likely hottest years on record (2014, 2015 and 2016) are \"meaningless\" because they are “well within the margin of error.”",
"itemReviewed": {
"@type": "CreativeWork",
"author": {
"@type": "Person",
"name": "James Inhofe",
"jobTitle": "U.S. Senator",
"image": "https://s3.amazonaws.com/share-the-facts/rating_images/factcheck.org/misleading.png",
"sameAs": [
"https://www.inhofe.senate.gov"
]
},
"datePublished": "2018-01-03",
"name": "Senate floor speech"
},
"reviewRating": {
"@type": "Rating",
"ratingValue": "6",
"alternateName": "Misleading",
"worstRating": "1",
"bestRating": "11",
"image": "https://s3.amazonaws.com/share-the-facts/rating_images/factcheck.org/misleading.png"
}
}
Where's the URL of the "Senate floor speech" in which James Inhofe made that claim? In the text of the article, FactCheck.org cites the Congressional Record, but that URL appears nowhere in the ClaimReview metadata.
If such URLs were routinely included, platforms could project fact-checks onto the targets, as well as the sources, of the claims they review. Browsers, when loading such URLs directly, could independently discover and announce related fact-checks. Fact-checks that share common targets could be correlated.
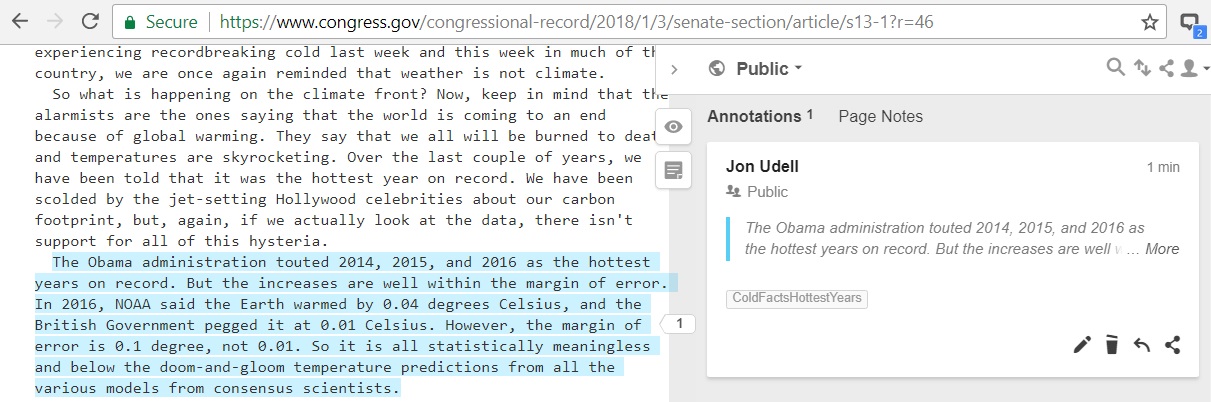
The ClaimReview data I've spot-checked lacks quality and consistency, and for this I don't fault the fact-checkers. Newsrooms with fewer hands on deck can ill afford extra data-entry chores. But what if we can streamline the data entry? Consider the claim evaluated in Cold Facts on the Globe's Hottest Years:

In order to cite the claim that's cited there, the fact-checker had to visit the source, select the claim, and copy it into the fact-check article.
Suppose that selection had been captured as an annotation:
Such an annotation is immediately useful to these stakeholders:
Fact-checker: Can more easily keep track of web resources related to an investigation.
Fact-checker's team: Can converse about the claim in the margin of its original source document.
Reader: Can follow a link to the annotated claim to see it in its original context.
Publisher: Can retrieve and display the claim automatically.
Fact-checking ecosystem: Can use a standard definition of the claim to coalesce fact-checks that target the same claim.
This screencast shows how an annotation-powered toolkit, developed initially to support the Digital Polarization Initiative, can deliver these benefits. Building on that example, here's a demo of an annotation-powered tool that makes production of ClaimReview data an integral part of the fact-checker's workflow.
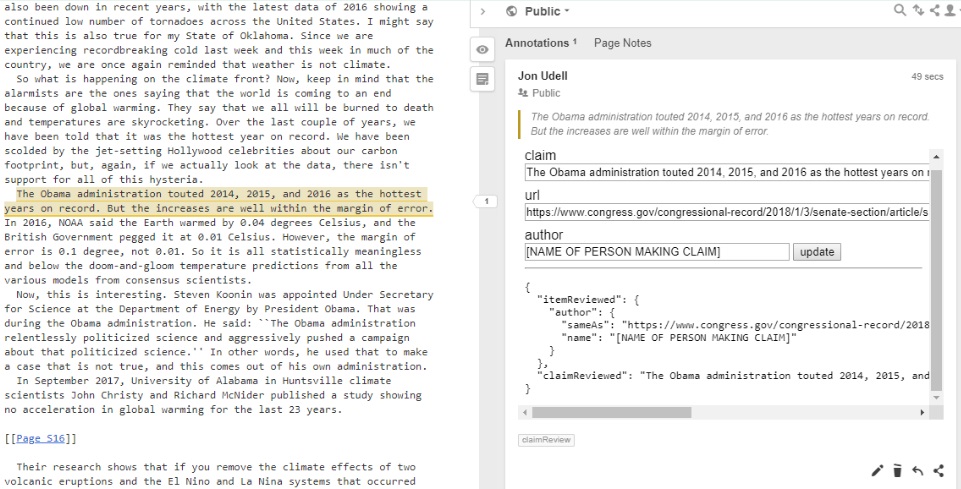
The workflow begins with a necessary first step: Select the claim in a source document. When that selection is made, the tool creates an annotation that immediately begins building the ClaimReview markup. Two key pieces of metadata -- the text of the claim, and the URL of the source document -- are automatically captured. Now the emerging bundle of metadata is born connected to the claim and aware of its original context.
This idea extends a technique introduced in Steel Wagstaff's Adding Interactivity to Web Annotation. He discusses a Hypothesis prototype that enables educators to embed H5P activities directly in annotations so that the activities anchor to selected statements in documents. Here the activity is fact-checking, and it anchors to the claim that is the target of the fact-check.
Other pieces of metadata can then be added incrementally. If information about the author of the claim can be gleaned from this context, for example, the tool can provide that automatically as well.
One piece of data entry that can't be fully automated is, of course, the verdict. Not only does it require human judgement, it may also be expressed in different ways. A Politifact article might rate a claim as a 2 of 7, and label it False. FactCheck.org might rate a claim as a 4 of 11 and label it Not the Whole Story. Such ratings are captured in workflows that are specific to each fact-checking organization. Those workflows are (I hope) already supported by form-filling activities. When such activities happen in the context of the claims they target, they can glean required information from that context, thus streamlining the form-filling workflow. The same mechanism produces standard descriptions of claims, in their original contexts, that help fact-checkers, publishers, readers, search engines refer to them in a common way.
We can all imagine the benefits that will flow from a robust ecosystem of ClaimReview metadata. Labels on search results will appear not only on URLs of articles that are targets of checked claims, but also on URLs of fact-check articles themselves. Such labels will also appear on the echoes of checked claims that are identified by human curators, machine learning systems, and most importantly, by systems that combine human and machine effort. But all these outcomes presume a level of data quality and consistency that the ClaimReview ecosystem has yet to achieve. How will we get there? In part, I propose, by embedding the right kind of tools into fact-checking workflows.