 As a result, my own XPath search mechanism can find that fragment. You can too, using IE or Mozilla, but I can't offer links to queries because the mechanism works by downloading a big swonk of XML into memory.
As a result, my own XPath search mechanism can find that fragment. You can too, using IE or Mozilla, but I can't offer links to queries because the mechanism works by downloading a big swonk of XML into memory.
XPath-aware blog engines are sprouting like weeds. Over at Sam Ruby's place, you can for example find entries that cite me. Kimbro Staken's Syncato should soon find its way on to more machines now that Rick Bradley has automated its prequisite installation hairball.
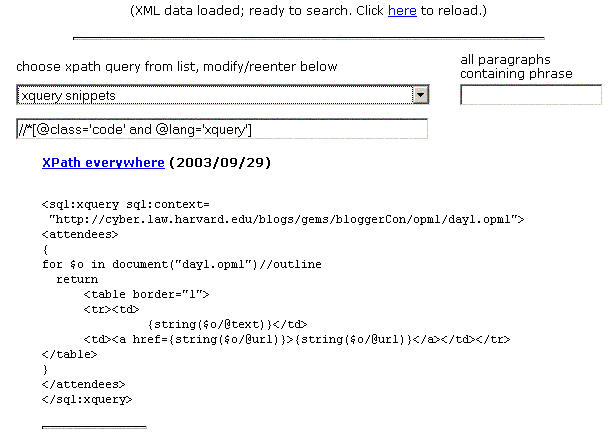
Meanwhile, OpenLink's Kingsley Idehen points out that his product, Virtuoso (which I've written about [1, 2]) can play this game too. Riffing on Kimbro's transclusion feature, which pulls the result of an XPath query into a blog posting, Kingsley shows off a dynamic XQuery-based transclusion that reformulates a chunk of XML -- specifically, the BloggerCon RSS feeds. The XQuery code that does this is:
<sql:xquery sql:context=
"http://cyber.law.harvard.edu/blogs/gems/bloggerCon/opml/day1.opml">
<attendees>
{
for $o in document("day1.opml")//outline
return
<table border="1">
<tr><td>
{string($o/@text)}</td>
<td><a href={string($o/@url)}>{string($o/@url)}</a></td></tr>
</table>
}
</attendees>
</sql:xquery>
Instructive! Note that if you use Mozilla's nifty View Selection Source on the above, you'll see this:
<pre class="code" lang="xquery">
...
</pre>
As a result, my own XPath search mechanism can find that fragment. You can too, using IE or Mozilla, but I can't offer links to queries because the mechanism works by downloading a big swonk of XML into memory.
We're obviously going to want linkable queries. I see two parallel paths forward. Along one path, dynamic blog servers will start to matter more than they have. (And we're going to see serious attention paid to XPath/XSLT performance.) Along another, services such as Technorati and Feedster will start to process XHTML content (when available) as well as RSS metadata.
One way or another, XML fragments are going to be in play. And then things are going to get really interesting.
Former URL: http://weblog.infoworld.com/udell/2003/09/29.html#a810