del.icio.us
 Back in February, I wrote an item on ways of using CSS class attributes to categorize content. Richard Soderberg wrote to ask if I'd looked into using Joshua Schachter's "social bookmarking" system del.icio.us. It seems I never replied (sorry, Richard), but here is my belated response. Although I knew about del.icio.us at the time, I was then exploring an emergent style of XHTML-driven categorization. I wanted to be able to write queries like this to find, for example, Python code fragments. And now I can.
Back in February, I wrote an item on ways of using CSS class attributes to categorize content. Richard Soderberg wrote to ask if I'd looked into using Joshua Schachter's "social bookmarking" system del.icio.us. It seems I never replied (sorry, Richard), but here is my belated response. Although I knew about del.icio.us at the time, I was then exploring an emergent style of XHTML-driven categorization. I wanted to be able to write queries like this to find, for example, Python code fragments. And now I can.
Recently, though, it occurred to me that there's no reason not to have the best of both worlds. The tagging discipline I've invented for myself can support some really powerful queries over my content, but realistically, it's not something that other people are likely to be doing anytime soon. But the tagging disciplines in del.icio.us, and also in Flickr, are far more accessible. Although conventional wisdom says that people can't be bothered to assign metadata tags, users of these systems do -- partly for their own benefit, and partly because the collaborative result is more than the sum of the individual efforts.
So I went through several hundred blog entries yesterday and assigned tags to them. Since I keep all of my blog content in a single XML file, it was surprisingly easy to do that, and only took about an hour. An entry in that file looks like this:
<item num="a1056">
<title>A strategic vision for dynamic languages</title>
<date>2004/08/09</date>
<body>
...xhtml...
</body>
</item>
I scanned through the file and added new <tags> elements like so:
<item num="a1056">
<title>A strategic vision for dynamic languages</title>
<date>2004/08/09</date>
<tags>python dynamiclanguages jvm clr</tags>
<body>
...xhtml...
</body>
</item>
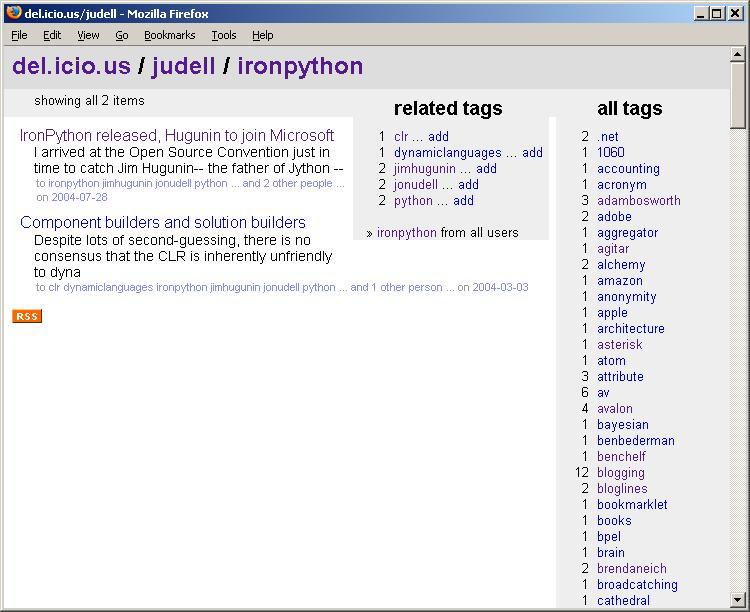
The first thing to notice here is that these new tags play nicely with my own query system. So here, for example, are the items tagged with 'ironpython'.
Now here's the equivalent view in del.icio.us. Here I can walk a clickpath from ironpython to dynamiclanguages to jvm to jython. That's fun, but the crucial difference is that I can expand to include all items that the del.icio.us community has tagged with 'ironpython'. The group mind knows things that I don't; I know things that it doesn't; use of a common tag effects a two-way transfer that benefits both.
To pump my blog entries into del.icio.us I used its API. The API is so dead simple that you can use curl -- the indispensable command-line tool for URL wrangling -- to post entries. So I wrote a Python script to transform my blog content into a bunch of curl invocations:
import libxml2, urllib, sys
xml = libxml2.parseFile('blog.xml')
items = xml.xpathEval('//item')
for item in items:
frag = item.xpathEval('@num')[0].content
title = item.xpathEval('title')[0].content
title = urllib.quote(title)
date = item.xpathEval('date')[0].content
body = item.xpathEval('body')[0].content
body = body.replace('\n','')
body = body[0:100]
body = urllib.quote(body)
try:
tags = item.xpathEval('tags')[0].content
tags = urllib.quote(tags)
url = 'http://weblog.infoworld.com/udell/' + date + '.html' + '#' + frag
url = urllib.quote(url)
post = """http://del.icio.us/api/posts/add?\
url=%s\
&description=%s\
&extended=%s\
&tags=%s\
&dt=%s-%s-%sT00:00:00Z""" % ( url, title, body, tags, date[0:4], date[5:7], date[8:10])
print 'curl -u ******:****** "%s"' % post
except:
sys.stderr.write ('%s\n' % title)
I echoed these curl invocations into a file and ran it as a shell script. Of course as soon as I'd done that, I wanted to make wholesale changes to my titles and tags. Although you can delete individual postings in the web interface to del.icio.us, there's no delete command in the API. But not to worry. There can evidently be only one posting for a given date and for a given referenced URL. So rerunning the curl invocations doesn't create duplicate postings, it updates the existing ones.
One of the wholesale changes I made was to add the tag 'jonudell' to all of the postings derived from my blog entries. That's so I can differentiate between postings derived from my blog entries and other bookmarks I might happen to make in the course of research. For each of my research projects, I accumulate a set of URLs. It's nuts, when you think about it, that after all these years I've never pushed that activity to the web where, in addition to being able to share bookmarks with myself across machines, I can both enrich and be enriched by a shared pool of bookmarks. So in addition to categorizing my own stuff (for my edification and for yours), we'll see if I can get into the habit of categorizing the bookmark trails I create as I explore various subjects.
One approach would be to assign a tag to each project. For example, this item was part of the research for the Longhorn cover story. If I were to assign a tag such as 'longhorn-udell-2004-04' to that item (along with, in this case, 'winfs' and 'jonudell'), I could also assign 'longhorn-udell-2004-04' and 'winfs' (but not 'jonudell') to related URLs that turned up in my research. Now these queries become possible:
http://del.icio.us/tag/winfs: All items tagged with 'winfs'
http://del.icio.us/tag/winfs+longhorn-udell-2004-04: All items tagged with 'winfs' and related to Jon's April cover story
http://del.icio.us/tag/winfs+longhorn-udell-2004-04+jonudell: All items tagged with 'winfs' and related to Jon's April cover story and posted to Jon's blog
Most people won't want to work this way, but there's a better than even chance that I will -- at least for major projects. We'll see how it goes.
Former URL: http://weblog.infoworld.com/udell/2004/08/11.html#a1057