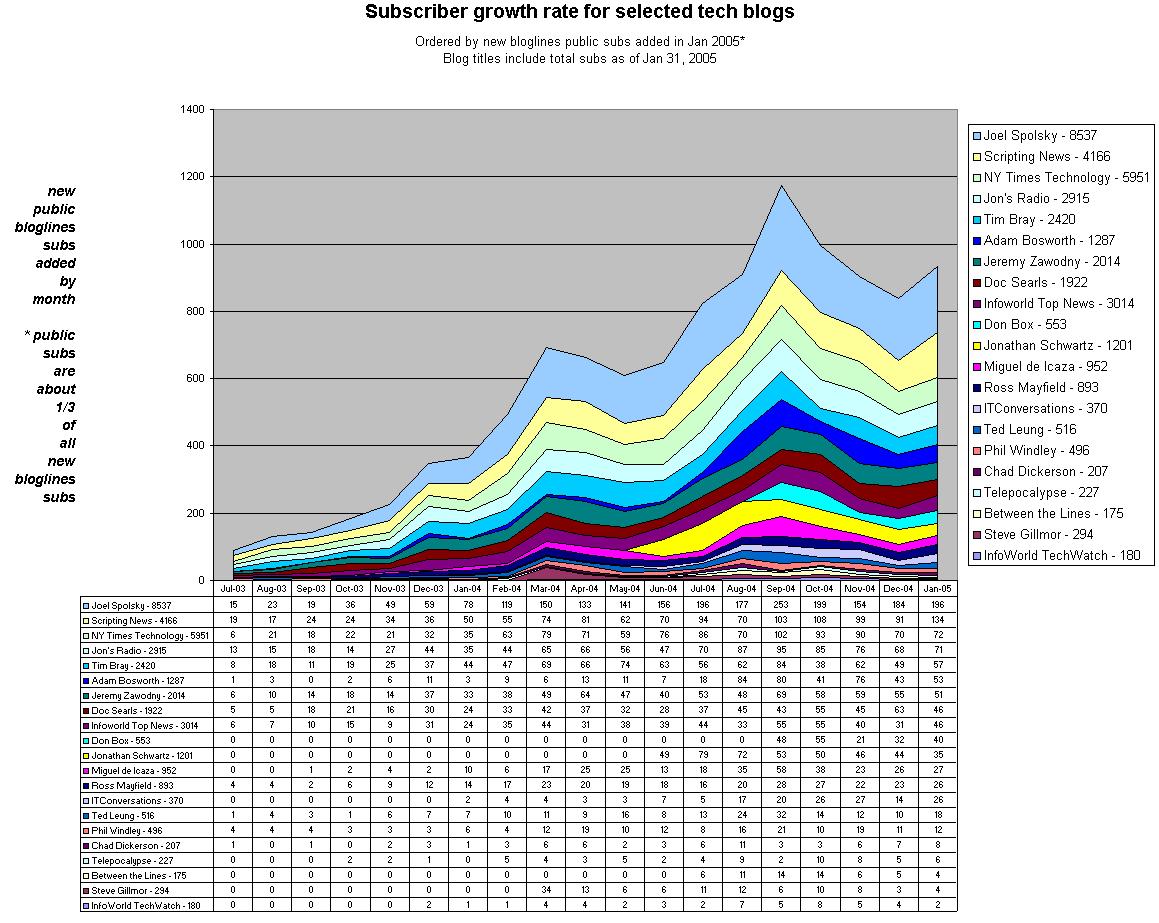
My earlier analysis of tech-blog subscription trends suggested that accelerating growth might have tailed off. But with final numbers for January now in, it appears that the foot is on the accelerator again. Plenty of caveats apply, of course. I'm assuming that Bloglines public subscribers are a reasonable proxy for all Bloglines subscribers, that Bloglines is a reasonable proxy for the whole blogosphere, and that the small sample of blogs I'm looking at is representative. On that basis, though, here's how it looks.
The original stacked area chart was here; the new version is:
The original line chart was here, the new version is:
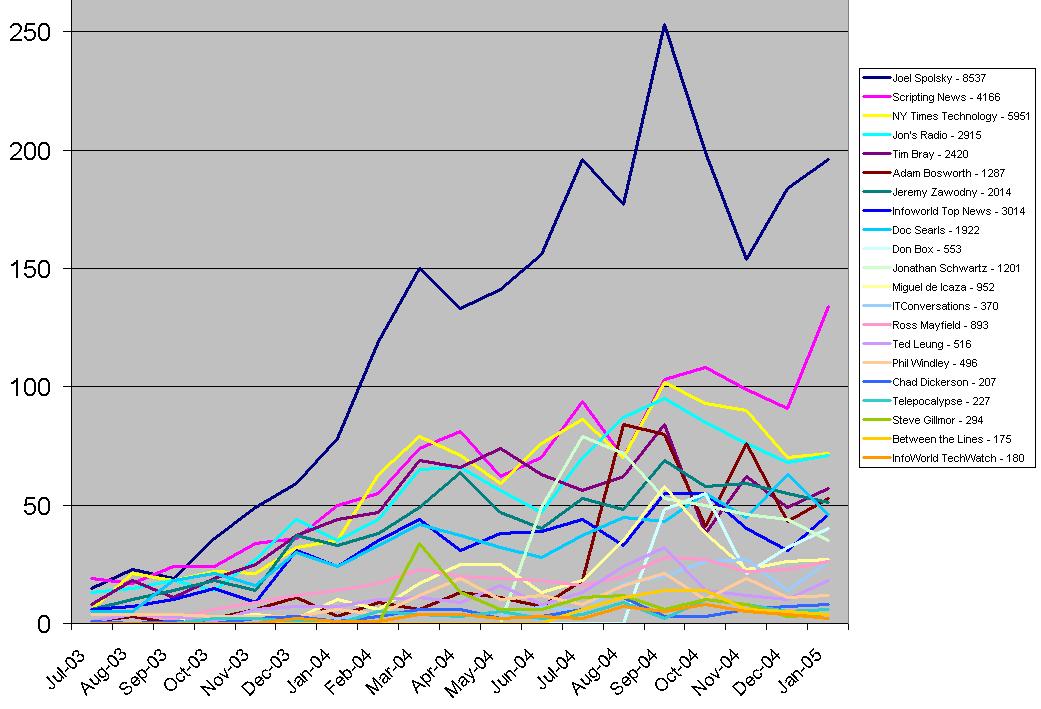
The overall trend is up, and most of the individual lines slope upward as well. If future months bring any surprises I may repeat this experiment. Meanwhile, for those interested in other blogs than the ones I chose to observe, here's the script I'm using. You can tweak the selected feeds as needed.
#!/usr/bin/python
import sys, urllib2, re, datetime
feedDict = {
'21': 'Scripting News' ,
'30': 'Doc Searls' ,
'39': 'Jon\'s Radio' ,
'42': 'Jeremy Zawodny' ,
'45': 'Joel Spolsky' ,
'1071': 'Tim Bray' ,
'1196': 'Phil Windley' ,
'3343': 'Ted Leung' ,
'4362': 'Chad Dickerson' ,
'4386': 'Adam Bosworth' ,
'5093': 'InfoWorld TechWatch' ,
'7281': 'Ross Mayfield' ,
'12636': 'Miguel de Icaza' ,
'33153': 'ITConversations' ,
'35411': 'Telepocalypse' ,
'48496': 'Infoworld Top News' ,
'116015': 'Steve Gillmor' ,
'297235': 'Jonathan Schwartz' ,
'296304': 'NY Times Technology' ,
'321242': 'Between the Lines' ,
'559101': 'Don Box' ,
}
monthDict = {
'January' : '01',
'February' : '02',
'March' : '03',
'April' : '04',
'May' : '05',
'June' : '06',
'July' : '07',
'August' : '08',
'September' : '09',
'October' : '10',
'November' : '11',
'December' : '12',
}
def newDict():
dict = {}
for year in ['2003','2004','2005']:
for month in monthDict.keys():
dict["%s-%s" % (year, monthDict[month])] = 0
return dict
def convertDate(l):
return "%s-%s" % ( l[1], monthDict[l[0]] )
def getFeedData(feed):
url = 'http://www.bloglines.com/userdir?siteid=%s' % feed
html = urllib2.urlopen(url).read()
totalSubs = re.findall ( '([\d]+) total subscribers' , html )[0]
publicSubs = re.findall ( '([\d]+) public subscribers' , html )[0]
dates = re.findall ( 'subscribed since (\w+) \d+, (\d{4,4})' , html )
dates = map ( convertDate, dates )
dict = newDict()
for date in dates:
try:
dict[date] += 1
except:
sys.stderr.write( "invalid date: %s\n" % date)
return ( dict, totalSubs, publicSubs )
output = ''
start = '2003-06'
now = datetime.datetime.now()
thisMonth = "%0.2d" % now.month
thisYear = now.year
end = "%s-%s" % ( thisYear, thisMonth )
for feed in feedDict.keys():
data = ''
(dict, totalSubs, publicSubs) = getFeedData(feed)
months = dict.keys()
months.sort()
for month in months:
if month > start and month <= end :
data += "<row><month>%s</month><count>%s</count></row>\n" % \
(month, dict[month])
output += """
<feed name="%s" totalSubs="%s" publicSubs="%s">
<data>
%s</data>
</feed>""" % ( feedDict[feed], totalSubs, publicSubs, data )
print "<feeds>" + output + "</feeds>"
The script only hits Bloglines once per feed, so it shouldn't cause any problems. It produces output like:
<feed name="Scripting News" totalSubs="4166" publicSubs="1248"> <data> <row><month>2003-07</month><count>19</count></row> ...etc... <row><month>2005-01</month><count>134</count></row> </data> </feed>
I'm using Excel's pivot-table/pivot-chart to visualize the XML data, but of course there are lots of other ways to do it.
If you use this code to publish any interesting results, you might consider tagging them with blogviz.
Redmond meetup: In other news, I've made a reservation at the Thai Ginger in Redmond's town center for this Friday, Feb 4, at 7PM. By all means drop by if you'd like. I took a wild guess and told them to expect 10-12 people.
Former URL: http://weblog.infoworld.com/udell/2005/02/02.html#a1164